
发布周期手记 —— 第一部分
我们第一次尝试用普通 CI/CD 流水线发布 LLM 时,构建变绿,部署成功,而客户支持团队在七分钟内就开始收到工单。
什么都没“坏“。4,200 个集成测试全部通过。延迟没变。200 OK 比率稳定。但在某一类法律领域的问题上,新模型悄悄开始打太极 —— 拒绝对上一个版本能正确回答的问题作出明确答复。没有任何测试发现这一点,因为我们当时还没写过这样的测试。
我们做了回滚,而回滚本身就是一场事故。模型构建产物存在于三处,提示模板存在于第四处,路由规则存在于第五处,彼此之间互不知情。花了刚好两个多小时才回到上一次稳定状态。那个窗口期里被服务以“打太极“回答的客户并不买账。
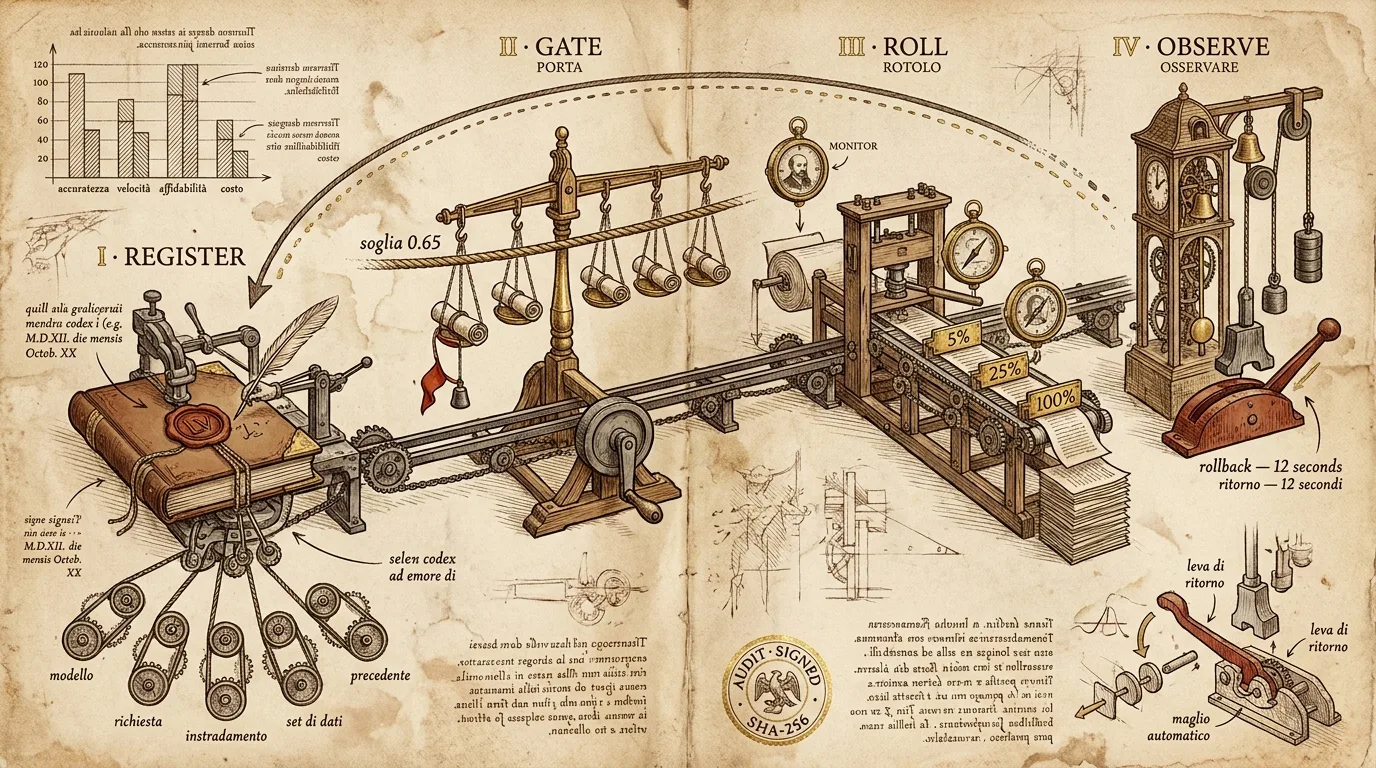
那次故障就是这条流水线存在的原因。下文写的是我们自己实际用来发布版本的流水线,也是我们通过 Divinci API 向客户交付他们自己发布流程的流水线。它分为四个阶段 —— 注册(register)、门禁(gate)、推送(roll)、观察(observe) —— 每一步都有一条不依赖人类清醒的回滚路径。
四个阶段

这些阶段是刻意僵化的。每一次发布都按此顺序穿过每个阶段。绕过评估的“热修复“路径并不存在 —— 我们试过一次。
阶段 1 —— 注册
一次发布不是一个模型权重文件。一次发布是一份不可变的清单,它打包了:
- 模型构建产物(HF repo + commit SHA,或一个 vIndex 补丁)
- 提示模板(每一个变量、每一条 system message)
- 路由规则(哪一类流量落到哪一个版本上)
- 用于计算门禁阈值的数据集版本
- 上一次发布的 SHA,以便回滚不存在歧义
curl -X POST https://api.divinci.ai/v1/releases \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{
"model_ref": "Divinci-AI/gemma-4-e2b@a7c91f",
"prompt_template_ref": "templates/legal-qa@v14",
"routing": { "domain": "legal" },
"dataset_version": "scored-qa-medical-v3",
"previous_release": "rel_8f72b1"
}'
# → { "release_id": "rel_a01c66", "manifest_sha256": "9abaeaf6..." }清单 SHA 是流水线里任何人会用到的唯一句柄。如果两个人各自部署“他们以为是同一个发布“而 SHA 不一致,流水线就拒绝该次部署。这条规则到目前已经替我们抓出过两个 bug。
阶段 2 —— 门禁
门禁是大多数 CI 流水线最容易做错的部分。Lighthouse 式的启发式指标 —— perplexity、BLEU、ROUGE —— 在回归集中于某一个领域时会放它通过。聚合分会把这种回归冲淡。
Divinci 的门禁运行的是发布清单注册时绑定的评分 QA 套件,并应用按类别的 Spearman 阈值:

上图中的发布在聚合门禁下能通过(均值 0.64 算是“接近“了)。它过不了 Divinci 的门禁,因为知识产权许可从此前的 0.68 暴跌到 0.41 —— 这正是 notebook 永远抓不到的那种局部回归。
我们做切片感知的门禁不是为了好玩。它就是当前一批 LLM 故障复盘里被直接点名的失败模式。Tianpan 的《“语义化版本谎言”》[6]记录的一次提示变更“通过了代码评审,部署时没有评估门禁,上了生产没有按用户做 A/B,也没有触发任何自动回滚“。让那起事故从“略烦“变成“灾难性“的原因是:回归集中在一个切片 —— 一个单独的用户旅程类别 —— 而聚合分依然稳。在 2026 年我们调研过的每一款 LLM 发布工具中,要么用单一全局分作门禁,要么根本不设门禁。没有一款把门禁切片。
门禁失败不是软警告。release_id 被标记为 gate_fail,清单被归档,任何部署命令都不会接受它。冷启动发布 —— 全新的模型,没有可对比的历史 Spearman —— 走一条一次性的 --force-gate-override 路径,需要书面理由;理由、用户 ID 与 gate_override_sha256 直接进入审计轨迹。覆盖路径存在,因为确有合理使用场景;审计轨迹存在,因为未来的你需要把那份理由再读一遍。
阶段 3 —— 推送
Divinci 的金丝雀意味着三个检查点:5%、25%、100%。在每个检查点,流水线会保持时长达到配置的驻留时间或请求量上限,二者取后到者。默认是 5% 阶段驻留 4 分钟 / 1,000 条请求,25% 阶段驻留 15 分钟 / 10,000 条请求。
在每个检查点,三项监控必须保持达标:
- p95 延迟在上一次发布的 p95 的 1.2 倍以内
- 5xx 比率在上一次发布的比率的 1.5 倍以内
- 输出质量监控:对近期生产请求持续回放给候选发布,由驱动阶段 2 的同一个校准过的评分员打分
第三项是其他发布流水线都没做的。SageMaker、KServe、BentoML、Vertex AI —— 它们都看延迟和错误率。没有一个会针对生产正在问的真实问题给候选输出打分。候选发布拿到生产当前发布刚收到的同样提示,在 5% 的镜像上运行,然后我们用校准过的评分员衡量候选答案的 Spearman ρ。5xx 比率可以一直干净,模型却悄悄打太极、拒答或者幻觉。我们见过这种情况。请求回放监控正是抓住它的东西。
回放集是有上限的 —— 我们把每个切片每个检查点的近期请求采样上限设为 50 条,确保成本可预测。在 5% 流量下打分大约需要 90 秒。比固定百分比的金丝雀慢一些,比等客户提工单快得多。
# roll 命令是"发出即不管"的。流水线会自己保持节奏。
curl -X POST https://api.divinci.ai/v1/releases/rel_a01c66/roll \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{ "strategy": "canary", "dwell_5pct_seconds": 240, "dwell_25pct_seconds": 900 }'
# → { "rollout_id": "rol_b3e2", "next_checkpoint_at": "2026-05-26T09:04:00Z" }阶段 4 —— 观察、回滚与凭证
这一阶段是这条流水线值得存在的理由。
发布完成后,观察器持续运行。它在 5% 的滚动请求回放样本上按分钟计算输出质量分。如果连续三分钟该分数低于回滚阈值(默认是门禁阈值的 0.85,例如门禁是 0.65 时为 0.55),回滚就自动触发。不发告警,不叫醒人,不开会讨论。
回滚本身只是一条指令:将路由重新指向清单里的 previous_release。因为上一次发布是一份完整打包的清单,每个组件 —— 权重、提示、路由、数据集 —— 都会原子化切回去。
然后凭证就开了。
每一项发布决策 —— 注册、门禁通过、门禁失败、门禁覆盖、检查点提升、检查点保持、自动回滚、人工回滚 —— 都会产出一份发布凭证:一份带 SHA-256 的 JSON 构件,与该客户上一份凭证以及该发布上一份凭证哈希链式相连,并按客户配置的时间表对外锚定。
当发布背后是开放权重模型 —— Gemma、Qwen、Llama、Mistral、GPT-OSS,任何权重可寻址且可编辑的模型 —— 凭证会内嵌一份 vIndex 证明:一种密码学证明,证明决策时刻在线的权重正是清单注册过的权重。这条路径满足较为严苛的合规要求(GDPR 第 17 条删除权、欧盟 AI 法案出处要求),因为你不仅能证明部署了什么,还能证明底层权重就是它所声称的样子。
当发布背后是闭源权重模型 —— OpenAI、Anthropic、Google,任何只通过不透明 API 服务的模型 —— 凭证依然覆盖决策链(用了哪份清单、哪个门禁结果、哪个监控读数、谁触发了哪个动作),但无法对底层权重作证,因为我们看不到它们。这不是流水线的局限;这是当提供方不开放权重时“可被验证的事物“的边界。在意这一区分的审计员会从凭证本身得到真实答案。
无论哪种情况,如今审计员能拿到的是日志。有了这条流水线,他们能拿到的是关于一切实际可证明之事的证明。我们在市场上没看到任何人发货这一能力。我们预计他们终会发 —— 欧盟 AI 法案的时间表让这件事最终不可避免。我们选择现在就发。
这些不是我们的数字 —— 它们是来自真实事故复盘、平台文档以及 DORA 框架的公开第一手数字。对比反差正是 Divinci 设计的动因。Atlassian 2022 年 4 月的故障[1]每个站点花了十二小时,因为状态散落在多个必须协调回一致的系统中。Cloudflare 2022 年 6 月的故障[2]用了四十四分钟才回退,按他们自己的话说,工程师互相在对方的回退之上又做了回退。AWS SageMaker 的金丝雀部署防护栏[4]明文规定回滚完全完成前默认有十分钟终止等待。DORA[3]对部署失败恢复的精英阈值是“一小时以内“ —— 那是高绩效组织被期望跨过的门槛,不是天花板。
十二秒也不是什么魔法数字。它就是路由层排空进行中请求、切换在线清单、跨区域确认新状态所需的时间。慢的部分在于排空进行中的请求。任何更快的路径都会在生成过程中丢响应。
这条流水线有什么是其他 LLM 发布工具没有的
构建之前,我们在 2026 年调研了十二款工具 —— LangSmith Deployment、W&B Models、MLflow、SageMaker Deployment Guardrails、Vertex AI Endpoints、Seldon Core、BentoCloud、KServe、Humanloop、Braintrust、Patronus AI、Arize Phoenix。它们聚类成两个阵营,中间没接上。
评估 CI 阵营 —— Braintrust、Humanloop、Patronus —— 在 PR 合并时根据离线评估分卡门。它们永远不会触碰运行中的服务。当模型已在生产、质量下滑时,它们会告警;回滚得交给别人去做。
服务金丝雀阵营 —— SageMaker Deployment Guardrails、KServe、Vertex AI、BentoCloud、Seldon Core —— 会拆分流量并自动回滚。但它们每一个都靠基础设施指标触发:p99 延迟、错误率、CloudWatch 告警。没有一个会在质量回归时自动回滚。它们做不到,因为它们没有在生产输出上运行的评分员。
“在 PR 合并时通过评估“与“在我们实际关心的用户旅程上对在线金丝雀进行评分“之间的缝隙,如今每个团队都得自己手工去缝。前文那篇博客把它点名为 2026 年的主导失败模式[6]。我们把它合上了。具体来说:
- 门禁是切片的。 针对人工锚定评分员的按领域 Spearman ρ,不是单一全局分。切片盲是每一个其他门禁的共性。
- 金丝雀监控的是输出质量,不仅仅是 p95。 把候选发布持续做请求回放,由驱动门禁的同一个评分员打分。这就是那段缺失的接缝。
- 每一项决策都产出发布凭证。 哈希链式、可对外锚定,采用支撑我们合规页面的 JSON-with-SHA-256 格式。对于开放权重模型支撑的发布 —— Gemma、Qwen、Llama、Mistral、GPT-OSS —— 凭证内嵌一份 vIndex 权重证明,审计员可以证明在线权重究竟是什么。对于闭源 API 支撑的发布,凭证覆盖决策链但不主张权重出处,因为提供方不开放权重。无论哪种,审计员拿到的都是关于实际可证明之事的证明,而不仅仅是日志。
仅此而已。通用金丝雀、版本注册表、基于基础设施指标的回滚 —— 这些是商品化能力。我们没有再写一个通用金丝雀。
这条流水线没解决的问题
三项坦诚的局限:
门禁的好坏只取决于数据集。 一份不覆盖客户实际使用领域的评分 QA 套件抓不到那个领域的回归。我们见过两次。两次客户的第一步动作都是发一份新的评分 QA 套件,而不是改模型。这是正确的动作。
回滚假设上一次发布是好的。 如果某个回归已经在线了三个版本而无人察觉,只回滚一次只能换来一个稍微没那么糟的模型。审计轨迹在这里能帮上忙 —— 你可以按 SHA 回滚到任何先前的清单,不止 N-1。
冷启动发布跳过金丝雀。 一个全新的模型没有生产流量可以对比,做金丝雀没有意义。我们改为强制 24 小时影子部署,只观察输出而不对外服务。它更慢,也更不方便。它也是唯一诚实的答案。
你能跑起来的最小版本
如果你想在不使用 Divinci 的情况下搭一套类似的东西,最小可行版本大致是:
- 一个把模型 + 提示 + 路由 + 数据集作为单一不可变构件存储、按内容哈希寻址的注册表
- 一个通过 Spearman ρ 与人工锚定面板校准过的评分员 —— 以及一个查询按切片得分而不仅是聚合的门禁判定
- 一个在检查点保持驻留并查询“新鲜度有限的质量监控“的流量切分器 —— 监控应把近期生产请求回放给候选发布,而不是只采样合成请求
- 一个状态可原子化切换的路由层 —— 包括提示模板,不只是权重
- 一份为每一项发布决策产出哈希链式、可对外锚定的凭证的审计日志 —— 当模型是开放权重时,额外内嵌一份权重证明,因为闭源 API 发布在权重层物理上无法被证明
大多数团队已经有 (1) 和 (3)。难做的部分是 (2)、(4) 和 (5)。Divinci 之所以存在,是因为我们先为自己把五项全做完了,然后意识到其他所有人最终也都会需要它们。
如果你想跳过自建,API 参考在这里,“Release Management” 一节中的发布端点就是这条流水线的整个表面。合规一侧 —— vIndex 凭证长什么样,以及它们如何映射到欧盟 AI 法案、GDPR 第 17 条、HIPAA 和 NIST AI RMF —— 在合规页面。本文中的每一条命令都是真实端点。
参考文献
- Atlassian —— Post-Incident Review: April 2022 Outage。文中原话:"加速版恢复 2 方案恢复一个站点大约用时 12 小时。"883 个客户站点完整恢复花了 14 天。状态散落在基础设施、备份和按站点验证上,使得每站点用时进入小时级而非分钟级。
- Cloudflare —— Cloudflare outage on June 21, 2022。文中逐字摘录的时间线:"06:58:根因找到并被理解。开始着手回退引发问题的变更…… 07:42:最后一次回退已完成。"从"我们知道要回退什么"到"回退完成"用了四十四分钟,部分原因是工程师互相在对方的回退之上又做了回退。
- DORA —— Software delivery performance metrics。"部署失败恢复时间"的精英表现者阈值被明文记录为不到一小时。低绩效者在 DORA 的历史报告中以"数周到数月"计量。
- AWS SageMaker —— Use canary traffic shifting 以及配套的 Auto-Rollback Configuration and Monitoring 页面。示例中
TerminationWaitInSeconds为 600(十分钟);MaximumExecutionTimeoutInSeconds的上限为 1800(三十分钟)。一旦告警在烘焙期触发,回滚就开始:"如果烘焙期内任何告警触发,SageMaker AI 会启动回滚,所有流量回到蓝色集群。" - Divinci AI —— 通过发布清单的原子化路由切换。在大约 100 个副本的服务上,十二秒就是进行中请求的排空时间;清单切换本身在亚秒级。该数字来自我们自己的服务,不是基准测试;让它成为可能的架构正是上文(阶段 1 —— 注册)描述的打包清单。
- Tianpan —— The Semver Lie: how an LLM minor update breaks production (April 2026)。文章直接点名该失败模式:"通过了代码评审,部署时没有评估门禁,上了生产没有按用户做 A/B,也没有触发任何自动回滚。"姊妹文 —— LLM postmortem template — fields SRE missed —— 列举了当前事故复盘系统性遗漏的切片 / 旅程 / 按用户字段。
关于此图上没有的内容做个说明。Kubernetes kubectl rollout undo 的耗时由你的 maxSurge / maxUnavailable 设置和 pod 预热决定,而不是命令本身,我们也找不到一手来源像上述四个来源那样发布一个实测数字 —— 所以我们就把它留空,而不是用估算填上。
本系列下一篇: 我们在自研 LM 上抓到的 10 次 CI/CD 发布失败,以及流水线的哪个阶段抓住了它们。 十次中有三次是聚合门禁本会放行的切片感知回归。再加两次是基础设施指标金丝雀本会提升的静默质量下滑。其余的是任何发布流水线本就该抓住的失败模式 —— 我们把它们列出来,是因为值得明说聚合门禁的流水线确实自己也能抓住其中哪些。
Ready to Build Your Custom AI Solution?
Discover how Divinci AI can help you implement RAG systems, automate quality assurance, and streamline your AI development process.
Get Started Today