
Заметки из релиз-цикла — Часть I
Когда мы впервые попытались выкатить LLM через обычный CI/CD-конвейер, билд прошёл зелёным, деплой удался, а служба поддержки начала получать тикеты уже через семь минут.
Ничего не «сломалось». Все 4 200 интеграционных тестов прошли. Латентность не изменилась. Доля 200 OK держалась стабильно. Но на определённом классе вопросов из правовой сферы новая модель тихо начала уходить от ответа — отказывалась давать ответ, который предыдущая версия давала корректно. Ни один тест этого не поймал, потому что мы такого ещё не написали.
Мы откатились, и сам по себе откат стал событием. Артефакт модели жил в трёх местах, шаблон промпта — в четвёртом, правила маршрутизации — в пятом, и ничто не знало ни о чём другом. На возврат к предыдущему рабочему состоянию ушло чуть больше двух часов. Клиенты, которым в это окно выдавали уход от ответа, не пришли в восторг.
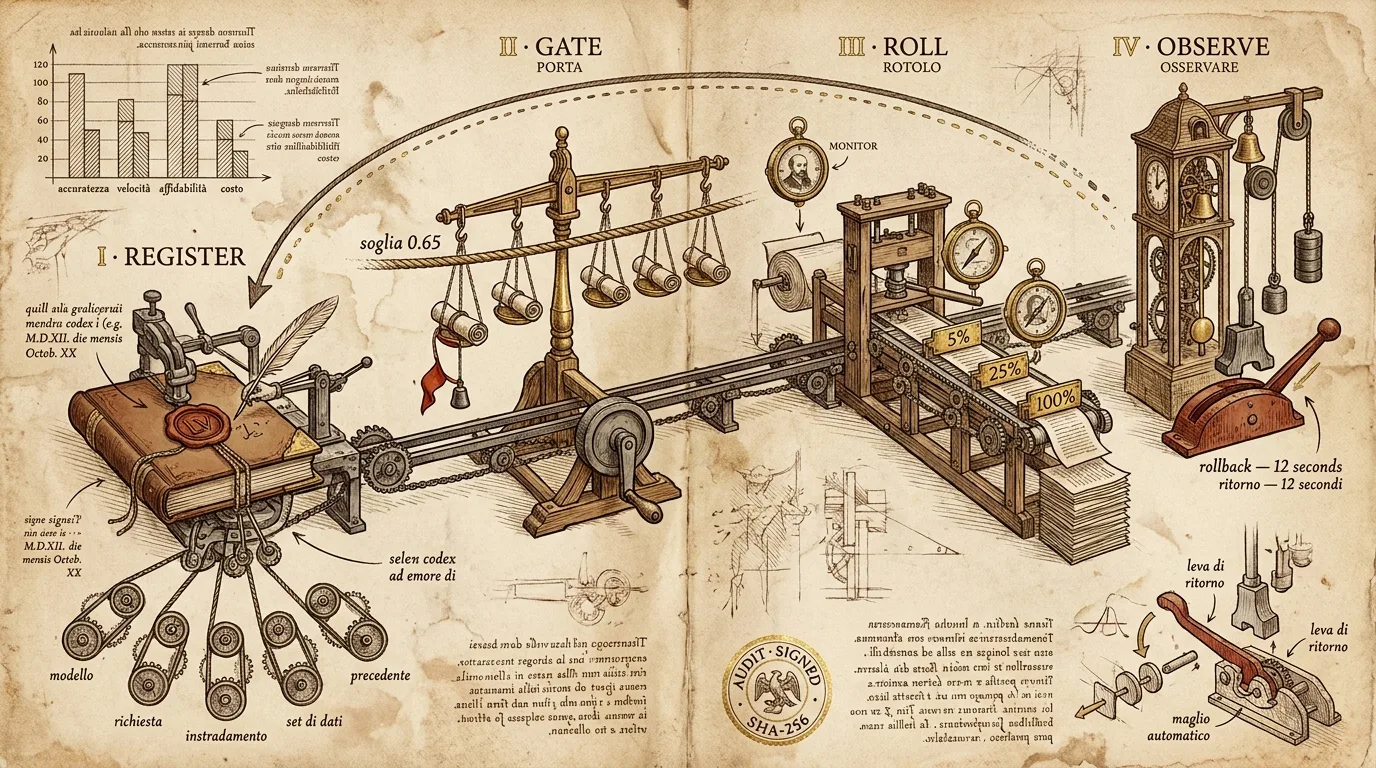
Этот инцидент — причина, по которой существует данный конвейер. Дальше — реальный конвейер, через который мы выпускаем собственные релизы и который мы открываем через Divinci API клиентам, выпускающим свои. У него четыре стадии — register, gate, roll, observe — и на каждом шаге есть путь отката, не требующий, чтобы человек не спал.
Четыре стадии

Стадии намеренно жёсткие. Каждый релиз проходит все стадии в этом порядке. Пути «hotfix», который обходит оценку, не существует — однажды мы это попробовали.
Стадия 1 — Register
Релиз — это не файл весов модели. Релиз — это неизменяемый манифест, который объединяет:
- Артефакт модели (HF-репозиторий + commit SHA или vIndex-патч)
- Шаблон промпта (каждую переменную, каждое system-сообщение)
- Правила маршрутизации (какой класс трафика попадает на какую версию)
- Версию датасета, по которой считались пороги гейта
- SHA предыдущего релиза, чтобы откат был однозначным
curl -X POST https://api.divinci.ai/v1/releases \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{
"model_ref": "Divinci-AI/gemma-4-e2b@a7c91f",
"prompt_template_ref": "templates/legal-qa@v14",
"routing": { "domain": "legal" },
"dataset_version": "scored-qa-medical-v3",
"previous_release": "rel_8f72b1"
}'
# → { "release_id": "rel_a01c66", "manifest_sha256": "9abaeaf6..." }SHA манифеста — единственный идентификатор, которым пользуется кто-либо в конвейере. Если двое выкатывают то, что они считают одним и тем же релизом, а SHA различаются, конвейер отклоняет деплой. С помощью этого правила мы уже поймали два бага.
Стадия 2 — Gate
Гейт — та часть, которую большинство CI-конвейеров делают неправильно. Эвристики в стиле Lighthouse — perplexity, BLEU, ROUGE — пропустят регрессию, если она сконцентрирована в одном домене. Агрегированные оценки её размывают.
Гейт Divinci прогоняет scored-QA-набор, с которым был зарегистрирован манифест релиза, и применяет покатегорийный порог Spearman:

Релиз с приведённой выше диаграммы прошёл бы агрегированный гейт (среднее 0,64 — «достаточно близко»). Гейт Divinci он не проходит, потому что лицензирование ИС обваливается с прежних 0,68 до 0,41 — ровно та локализованная регрессия, которую ноутбук никогда не ловит.
Мы не придумали гейтинг с учётом срезов ради забавы. Это прямо названный режим отказа в актуальной волне постмортемов LLM. Разбор Тяньпаня «The Semver Lie»[6] описывает изменение промпта, которое «прошло код-ревью, выкатилось без eval-гейтов, попало в продакшн без покозырьного A/B и не вызвало никакого автоматического отката». То, что сделало этот инцидент катастрофическим, а не просто неприятным, — регрессия была сконцентрирована в одном срезе, в одном классе пользовательского сценария, тогда как агрегат держался. Каждый инструмент релизов LLM, который мы рассматривали в 2026 году, либо гейтит по единому глобальному баллу, либо не гейтит вовсе. Ни один не разрезает гейт по срезам.
Сбой гейта — не мягкое предупреждение. release_id помечается как gate_fail, манифест архивируется, и ни одна команда deploy его не примет. Холодные стартовые релизы — совершенно новая модель, для которой нет исторического Spearman для сравнения, — проходят через одноразовый путь --force-gate-override, требующий письменного обоснования; обоснование, ID пользователя и gate_override_sha256 напрямую уходят в аудит-трейл. Override существует, потому что для него есть законные ситуации; аудит-трейл существует, потому что вам в будущем нужно будет прочитать это обоснование.
Стадия 3 — Roll
Canary в Divinci — это три контрольные точки: 5%, 25%, 100%. На каждой точке конвейер выдерживает либо заданное время простоя, либо заданное количество запросов — что наступит позже. По умолчанию это 4 минуты / 1 000 запросов на 5%, 15 минут / 10 000 запросов на 25%.
На каждой контрольной точке должны выдерживаться три монитора:
- p95-латентность в пределах 1,2× от p95 предыдущего релиза
- Доля 5xx в пределах 1,5× от доли предыдущего релиза
- Монитор качества ответов: непрерывная прокрутка свежих продакшен-трейсов через релиз-кандидат, оцениваемая тем же калиброванным судьёй, который работал на Стадии 2
Третий — тот, которого нет ни у одного другого пайплайна релизов. SageMaker, KServe, BentoML, Vertex AI — все они смотрят на латентность и долю ошибок. Ни один из них не оценивает ответы кандидата по реально задаваемым прямо сейчас вопросам продакшена. Кандидат получает те же промпты, что только что получил активный релиз, прогоняет их на 5%-зеркале, и мы измеряем Spearman ρ ответов кандидата против калиброванного грейдера. Доля 5xx может оставаться чистой, пока модель тихо уходит от ответа, отказывает или галлюцинирует. Мы это наблюдали. Именно монитор повторного прогона трейсов ловит такое.
Набор для прогона ограничен — мы ставим потолок 50 свежих трейсов на срез на контрольную точку, чтобы стоимость была предсказуемой. Оценка занимает около 90 секунд при 5% трафика. Медленнее, чем плоский процентный canary, быстрее, чем ждать клиентского тикета.
# Команда roll — fire-and-forget. Конвейер удерживается сам.
curl -X POST https://api.divinci.ai/v1/releases/rel_a01c66/roll \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{ "strategy": "canary", "dwell_5pct_seconds": 240, "dwell_25pct_seconds": 900 }'
# → { "rollout_id": "rol_b3e2", "next_checkpoint_at": "2026-05-26T09:04:00Z" }Стадия 4 — Observe, rollback и расписка
Это стадия, ради которой конвейер и существует.
Наблюдатель работает непрерывно после завершения раскатки. Он вычисляет поминутную оценку качества ответов на скользящей 5%-выборке прогонки трейсов. Если оценка опускается ниже порога отката (по умолчанию 0,85 от порога гейта, то есть 0,55 при гейте 0,65) три минуты подряд, откат срабатывает автоматически. Без пейджера, без человека, без обсуждения.
Сам по себе откат — одна инструкция: перенацелить маршрутизацию на previous_release из манифеста. Поскольку предыдущий релиз был полностью собранным манифестом, все компоненты — веса, промпт, маршрутизация, датасет — переключаются атомарно.
Затем срабатывает расписка.
Каждое релизное решение — register, gate-pass, gate-fail, gate-override, checkpoint-promote, checkpoint-hold, auto-rollback, manual-rollback — порождает расписку о релизе: JSON-with-SHA-256-артефакт, хеш-связанный с предыдущей распиской по этому клиенту и с предыдущей распиской по этому релизу, заякоренный внешним способом по графику, который настраивает клиент.
Когда за релизом стоит модель с открытыми весами — Gemma, Qwen, Llama, Mistral, GPT-OSS, всё, где веса адресуемы и редактируемы, — расписка встраивает vIndex-аттестацию: криптографическое доказательство того, что активные веса в момент решения — это те же веса, которые зарегистрировал манифест. Этот путь удовлетворяет более жёсткие compliance-требования (право на стирание по статье 17 GDPR, провенанс по EU AI Act), потому что вы можете доказать не только что было задеплоено, но и что нижележащие веса — именно то, чем себя называют.
Когда за релизом стоит модель с закрытыми весами — OpenAI, Anthropic, Google, всё, что обслуживается только через непрозрачный API, — расписка по-прежнему покрывает цепочку решений (какой манифест, какой результат гейта, какое показание монитора, какой пользователь запустил какое действие), но не может удостоверить нижележащие веса, потому что мы их не видим. Это не ограничение конвейера; это ограничение того, что вообще верифицируемо, когда провайдер не отдаёт веса. Аудиторы, которым это различие важно, получают честный ответ в самой расписке.
В любом случае сегодня аудиторы получают логи. С этим конвейером они получают доказательства всего, что действительно доказуемо. Мы не видели на рынке никого, кто это поставлял бы. Думаем, ещё поставят — таймлайн EU AI Act делает это в конечном счёте неизбежным. Мы решили поставить это сейчас.
Это не наши цифры — это опубликованные значения из первичных источников: реальных постмортемов, документации платформ и фреймворка DORA. Контраст и мотивирует архитектуру Divinci. Сбой Atlassian в апреле 2022[1] занял двенадцать часов на сайт, потому что состояние было размазано по нескольким системам, которые нужно было согласованно вернуть в согласие. Сбой Cloudflare в июне 2022[2] занял сорок четыре минуты на откат, потому что, по их собственным словам, инженеры пересекались на откатах друг друга. Canary-guardrails AWS SageMaker[4] в документации описаны с дефолтным десятиминутным ожиданием завершения, прежде чем откат полностью отработает. Порог DORA[3] для элитного восстановления после неуспешного деплоя — «менее одного часа», и это планка, которую должна перепрыгивать высокопроизводительная организация, а не потолок.
Двенадцать секунд — тоже не магическое число. Это время, нужное слою маршрутизации, чтобы добить in-flight-запросы, поменять активный манифест и подтвердить новое состояние по регионам. Медленная часть — добивание in-flight. Более быстрого пути, который не оборвал бы ответы посреди генерации, нет.
Что это такое, чем не являются другие инструменты релизов LLM
Перед тем как построить это, в 2026 году мы изучили двенадцать других инструментов — LangSmith Deployment, W&B Models, MLflow, SageMaker Deployment Guardrails, Vertex AI Endpoints, Seldon Core, BentoCloud, KServe, Humanloop, Braintrust, Patronus AI, Arize Phoenix. Они кучкуются в два лагеря, которые так и не встречаются.
Лагерь eval-CI — Braintrust, Humanloop, Patronus — гейтит мерджи PR по офлайн-eval-оценкам. К запущенному сервису они не прикасаются. Когда модель в продакшене и качество падает, они алертят; откатывать должен кто-то другой.
Лагерь serving-canary — SageMaker Deployment Guardrails, KServe, Vertex AI, BentoCloud, Seldon Core — делят трафик и откатываются автоматически. Но каждый из них триггерится на инфраметрики: p99-латентность, доля ошибок, алармы CloudWatch. Ни один не откатывается автоматически по регрессии качества. Не может — потому что у них нет судьи, работающего на продакшен-выходе.
Шов между «прошёл eval при мердже PR» и «живой canary, оцениваемый по тем пользовательским сценариям, которые нам реально важны» — это ручная передача, которую каждой команде приходится наводить самой. Тот пост называет это доминирующим режимом отказа 2026 года[6]. Мы этот шов закрыли. Конкретно:
- Гейт разрезан по срезам. Покатегорийный Spearman ρ против калиброванного по человеку грейдера, а не единый глобальный балл. Слепота к срезам — то, чем грешит любой другой гейт.
- Canary смотрит на качество ответов, а не только на p95. Непрерывная прогонка трейсов через кандидата, оцениваемая тем же судьёй, который работал на гейте. Это и есть недостающий шов.
- Каждое решение порождает расписку о релизе. Хеш-связанная, внешне заякоряемая, в формате JSON-with-SHA-256, на котором стоят наши compliance-страницы. Для бэкенда на модели с открытыми весами — Gemma, Qwen, Llama, Mistral, GPT-OSS — расписка встраивает vIndex-аттестацию весов, чтобы аудиторы могли доказать, какими действительно были живые веса. Для бэкенда на закрытом API расписка покрывает цепочку решений, но не претендует на провенанс весов, потому что провайдер не отдаёт веса. В любом случае аудиторы получают доказательства того, что действительно доказуемо, а не только логи.
Вот и всё. Универсальный canary, реестр версий, откат по инфраметрикам — это commodity. Универсальный canary мы не писали.
Что это не решает
Три честных ограничения:
Гейт настолько хорош, насколько хорош датасет. Scored-QA-набор, не покрывающий домен, который клиент реально использует, не поймает регрессии в этом домене. Мы видели это дважды. Оба раза первым шагом клиента было выкатить новый scored-QA-набор, а не менять модель. Это правильный ход.
Откат предполагает, что предыдущий релиз был хорошим. Если регрессия живёт три релиза и никто её не заметил, откат на один релиз даёт лишь чуть менее плохую модель. Аудит-трейл здесь помогает — можно откатиться на любой прошлый манифест по SHA, не только на N-1.
Холодные стартовые релизы обходят canary. Совершенно новую модель, у которой нет продакшен-трафика для сравнения, осмысленно canary не сделать. Мы вместо этого принудительно делаем 24-часовой shadow-деплой, наблюдающий за выходами, не отдавая их пользователям. Это медленнее и менее удобно. Это также единственный честный ответ.
Минимальная версия этого, которую можно поднять
Если хочется поднять что-то подобное без Divinci, минимально жизнеспособная версия примерно такая:
- Реестр, хранящий модель + промпт + маршрутизацию + датасет как единый неизменяемый артефакт, адресуемый по хешу содержимого
- Судья, калиброванный против панели людей по Spearman ρ, и решение гейта, сверяющееся с покатегорийными оценками, а не только с агрегатом
- Сплиттер трафика, удерживающий контрольные точки и сверяющийся с монитором качества, ограниченным по свежести, — где монитор прогоняет свежие продакшен-трейсы через кандидата, а не сэмплирует синтетические
- Слой маршрутизации, состояние которого можно поменять атомарно — включая шаблон промпта, а не только веса
- Аудит-лог, выпускающий хеш-связанную, внешне заякоряемую расписку для каждого решения о релизе, плюс встраиваемая аттестация весов, когда модель с открытыми весами, потому что релизы на закрытом API физически нельзя удостоверить на уровне весов
У большинства команд уже есть (1) и (3). Болезненные части — (2), (4) и (5). Divinci существует потому, что мы построили все пять сначала для себя, а потом поняли, что они понадобятся и всем остальным.
Если хочется пропустить стройку, API-референс — здесь, а эндпоинты релизов в разделе «Release Management» — это и есть вся поверхность данного конвейера. Сторона compliance — как выглядят те самые vIndex-расписки и как они ложатся на EU AI Act, статью 17 GDPR, HIPAA и NIST AI RMF — на странице compliance. Каждая команда в этом посте — реальный эндпоинт.
Литература
- Atlassian — Post-Incident Review: April 2022 Outage. Из разбора: «Ускоренный подход Restoration 2 занимал примерно 12 часов на восстановление одного сайта». Полное восстановление 883 клиентских сайтов заняло 14 дней. Состояние, размазанное по инфраструктуре, бэкапам и валидации каждого сайта, загоняет «время на сайт» в часы, а не в минуты.
- Cloudflare — Cloudflare outage on June 21, 2022. Таймлайн, дословно процитированный в посте: «06:58: первопричина найдена и понята. Начинается работа над откатом проблемного изменения… 07:42: последний из откатов завершён». Сорок четыре минуты от «мы знаем, что откатывать» до «откат сделан», отчасти потому что инженеры пересекались на откатах друг друга.
- DORA — Software delivery performance metrics. Порог «времени восстановления после неуспешного деплоя» для элитного performer-уровня задокументирован как менее одного часа. Низкие performer-команды в исторических отчётах DORA измеряют это в неделях-месяцах.
- AWS SageMaker — Use canary traffic shifting и сопровождающая страница Auto-Rollback Configuration and Monitoring. В примере
TerminationWaitInSecondsравно 600 (десять минут);MaximumExecutionTimeoutInSecondsограничено 1800 (тридцать минут). Откат стартует в течение окна выдержки, как только сработал аларм: «Если в период выдержки сработает любой из алармов, SageMaker AI инициирует откат и весь трафик возвращается на blue-флот». - Divinci AI — атомарное переключение маршрутизации через манифест релиза. Двенадцать секунд — это время добивания in-flight на сервисе из ~100 реплик; сама смена манифеста — субсекунда. Цифра — из нашего сервиса, не бенчмарк; архитектура, делающая её возможной, — это собранный манифест, описанный выше (Стадия 1 — Register).
- Tianpan — The Semver Lie: how an LLM minor update breaks production (April 2026). Разбор прямо называет шаблон отказа: «прошло код-ревью, выкатилось без eval-гейтов, попало в продакшн без покозырьного A/B и не вызвало никакого автоматического отката». Сопутствующий пост — LLM postmortem template — fields SRE missed — перечисляет поля по срезам/сценариям/пользователям, которые нынешние постмортемы систематически опускают.
Заметка о том, чего на диаграмме нет. Время kubectl rollout undo в Kubernetes определяется вашими настройками maxSurge / maxUnavailable и прогревом подов, а не самой командой, и мы не нашли первичного источника, публикующего измеренное число в том же духе, что и четыре источника выше, — поэтому решили не вписывать оценку и оставить эту строку пустой.
Следующее в серии: 10 отказов CI/CD-релизов, которые мы поймали в кастомных LM, и какая стадия конвейера ловит каждый из них. Три из десяти — регрессии с учётом срезов, которые агрегированный гейт пропустил бы в продакшн. Ещё две — тихие падения качества, которые canary по инфраметрикам бы повысил. Остальные — режимы отказа, которые любой релиз-конвейер обязан ловить; мы перечисляем их, потому что стоит проговорить вслух, какие из них агрегированно-гейтящийся конвейер действительно ловит сам.
Ready to Build Your Custom AI Solution?
Discover how Divinci AI can help you implement RAG systems, automate quality assurance, and streamline your AI development process.
Get Started Today