
Notas do Ciclo de Release — Parte I
A primeira vez que tentamos enviar um LLM por um pipeline normal de CI/CD, o build ficou verde, o deploy foi bem-sucedido e o suporte ao cliente começou a abrir tickets em sete minutos.
Nada havia “quebrado”. Todos os 4.200 testes de integração passaram. A latência permaneceu inalterada. A taxa de 200 OK se manteve estável. Mas em uma classe específica de pergunta do domínio jurídico, o novo modelo havia silenciosamente começado a se esquivar — recusando-se a se comprometer com uma resposta que a versão anterior havia respondido corretamente. Nenhum teste pegou isso porque ainda não tínhamos escrito um.
Fizemos rollback, e o próprio rollback foi um evento. O artefato do modelo vivia em três lugares, o template de prompt vivia em um quarto, as regras de roteamento viviam em um quinto, e nada sabia sobre nada mais. Levou pouco mais de duas horas para retornar ao estado bom anterior. Os clientes que receberam uma resposta evasiva durante essa janela não ficaram impressionados.
Aquele outage é a razão pela qual este pipeline existe. O que segue é o pipeline real pelo qual enviamos nossos próprios releases, e o que expomos através da API da Divinci para clientes que enviam os deles. Ele tem quatro estágios — registrar, gatear, rolar, observar — e cada passo tem um caminho de rollback que não depende de um ser humano estar acordado.
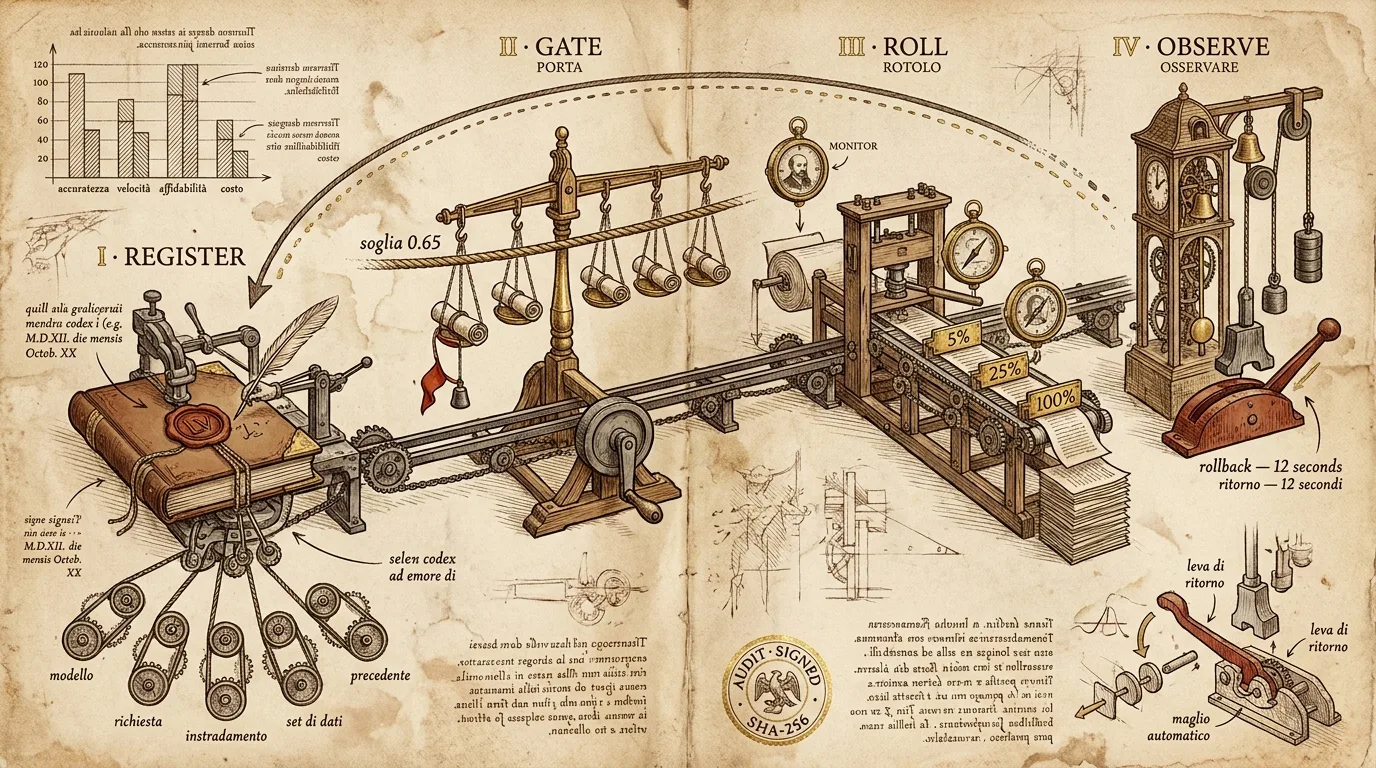
Os quatro estágios

Os estágios são intencionalmente rígidos. Todo release passa por todos os estágios nesta ordem. Um caminho de “hotfix” que pula a avaliação não existe — tentamos isso uma vez.
Estágio 1 — Registrar
Um release não é um arquivo de pesos do modelo. Um release é um manifesto imutável que agrupa:
- O artefato do modelo (repo HF + commit SHA, ou um patch vIndex)
- O template de prompt (cada variável, cada mensagem de sistema)
- As regras de roteamento (qual classe de tráfego cai em qual versão)
- A versão do dataset usada para computar os limiares do gate
- O SHA do release anterior, para que o rollback seja inequívoco
curl -X POST https://api.divinci.ai/v1/releases \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{
"model_ref": "Divinci-AI/gemma-4-e2b@a7c91f",
"prompt_template_ref": "templates/legal-qa@v14",
"routing": { "domain": "legal" },
"dataset_version": "scored-qa-medical-v3",
"previous_release": "rel_8f72b1"
}'
# → { "release_id": "rel_a01c66", "manifest_sha256": "9abaeaf6..." }O SHA do manifesto é o único identificador que qualquer um no pipeline jamais usa. Se duas pessoas fizerem deploy do que acham ser o mesmo release e os SHAs divergirem, o pipeline rejeita o deploy. Já capturamos dois bugs com essa regra.
Estágio 2 — Gatear
O gate é a parte que a maioria dos pipelines de CI faz errado. Heurísticas estilo Lighthouse — perplexidade, BLEU, ROUGE — vão deixar passar uma regressão se a regressão estiver concentrada em um domínio. Pontuações agregadas a diluem.
O gate da Divinci roda a suíte scored-QA com a qual o manifesto de release foi registrado e aplica um limiar Spearman por categoria:

O release no gráfico acima passaria em um gate agregado (média de 0,64 é “perto o suficiente”). Ele falha no gate da Divinci porque licenciamento de PI despenca de 0,68 para 0,41 — exatamente o tipo de regressão localizada que um notebook nunca pega.
Não inventamos gating por slice por diversão. É o modo de falha diretamente nomeado na atual safra de postmortems de LLM. O texto de Tianpan “The Semver Lie”[6] descreve uma mudança de prompt que “passou no code review, foi deployada sem eval gates, chegou à produção sem A/B por usuário e não disparou rollback automático”. O que tornou aquele incidente catastrófico em vez de meramente irritante foi que a regressão estava concentrada em um slice — uma única classe de jornada de usuário — enquanto o agregado se mantinha. Toda ferramenta de release de LLM que pesquisamos em 2026 ou gateia em uma única pontuação global, ou não gateia. Nenhuma delas fatia o gate.
Uma falha de gate não é um aviso leve. O release_id é marcado como gate_fail, o manifesto é arquivado, e nenhum comando de deploy o aceitará. Releases de cold-start — um modelo novinho em folha sem Spearman histórico para comparar — passam por um caminho único --force-gate-override que requer uma justificativa escrita; a justificativa, o ID do usuário e um gate_override_sha256 vão direto para a trilha de auditoria. O override existe porque há situações legítimas para ele; a trilha de auditoria existe porque o você-do-futuro precisa ler a justificativa.
Estágio 3 — Rolar
Um canário na Divinci significa três checkpoints: 5%, 25%, 100%. Em cada checkpoint, o pipeline segura pelo tempo de espera configurado ou pela contagem de requests configurada, o que for maior. O padrão é 4 minutos / 1.000 requests em 5%, 15 minutos / 10.000 requests em 25%.
Em cada checkpoint, três monitores precisam se manter:
- latência p95 dentro de 1,2× do p95 do release anterior
- taxa de 5xx dentro de 1,5× da taxa do release anterior
- Monitor de qualidade de saída: um replay contínuo de traços recentes de produção através do release candidato, pontuado pelo mesmo juiz calibrado que alimentou o Estágio 2
O terceiro é aquele que nenhum outro pipeline de release oferece. SageMaker, KServe, BentoML, Vertex AI — todos eles observam latência e taxa de erro. Nenhum deles pontua as saídas do candidato contra as perguntas reais que a produção está fazendo agora. O candidato recebe os mesmos prompts que o release ativo acabou de receber, os roda em um mirror de 5%, e medimos o ρ de Spearman das respostas do candidato contra o avaliador calibrado. A taxa de 5xx pode permanecer limpa enquanto o modelo silenciosamente se esquiva, recusa ou alucina. Já vimos isso acontecer. O monitor de replay de traços é o que pega.
O conjunto de replay é limitado — limitamos a 50 traços recentes por slice por checkpoint para que o custo seja previsível. A avaliação leva cerca de 90 segundos a 5% do tráfego. Mais lento que um canário de porcentagem fixa, mais rápido que esperar um cliente abrir um ticket.
# O comando roll é fire-and-forget. O pipeline se segura sozinho.
curl -X POST https://api.divinci.ai/v1/releases/rel_a01c66/roll \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{ "strategy": "canary", "dwell_5pct_seconds": 240, "dwell_25pct_seconds": 900 }'
# → { "rollout_id": "rol_b3e2", "next_checkpoint_at": "2026-05-26T09:04:00Z" }Estágio 4 — Observar, fazer rollback e o recibo
Este é o estágio que justifica a existência do pipeline.
O observador roda continuamente após o rollout completar. Ele computa uma pontuação de qualidade de saída por minuto em uma amostra rolante de replay de 5% dos traços. Se a pontuação cair abaixo do limiar de rollback (padrão: 0,85 do limiar do gate, então 0,55 se o gate foi 0,65) por três minutos consecutivos, o rollback dispara automaticamente. Sem pager, sem humano, sem debate.
O rollback em si é uma única instrução: re-apontar o roteamento para previous_release do manifesto. Como o release anterior era um manifesto totalmente agrupado, cada componente — pesos, prompt, roteamento, dataset — vira atomicamente.
Então o recibo dispara.
Cada decisão de release — registrar, gate-pass, gate-fail, gate-override, checkpoint-promote, checkpoint-hold, auto-rollback, manual-rollback — emite um recibo de release: um artefato JSON-com-SHA-256, encadeado por hash ao recibo anterior para esse cliente e ao recibo anterior para esse release, ancorado externamente em um cronograma que o cliente configura.
Quando o release é respaldado por um modelo open-weights — Gemma, Qwen, Llama, Mistral, GPT-OSS, qualquer coisa onde os pesos sejam endereçáveis e editáveis — o recibo embute uma atestação vIndex: uma prova criptográfica de que os pesos ativos no momento da decisão são os pesos que o manifesto registrou. Esse é o caminho que satisfaz as exigências mais duras de compliance (Artigo 17 do GDPR — direito ao esquecimento, proveniência do EU AI Act) porque você pode provar não apenas o que foi deployado, mas que os pesos subjacentes são o que dizem ser.
Quando o release é respaldado por um modelo closed-weights — OpenAI, Anthropic, Google, qualquer coisa servida apenas via uma API opaca — o recibo ainda cobre a cadeia de decisão (qual manifesto, qual resultado de gate, qual leitura de monitor, qual usuário disparou qual ação), mas não pode atestar os pesos subjacentes, porque não conseguimos vê-los. Isso não é uma limitação do pipeline; é uma limitação do que é verificável quando o provedor não expõe os pesos. Auditores que se importam com essa distinção recebem a resposta verdadeira no próprio recibo.
De qualquer forma, auditores hoje recebem logs. Com este pipeline, eles recebem provas de tudo o que é de fato provável. Não vimos mais ninguém no mercado oferecendo isso. Esperamos que outros venham — os prazos do EU AI Act tornam isso eventualmente inevitável. Optamos por oferecer agora.
Estes não são nossos números — são números publicados de fontes primárias de postmortems reais, documentação de plataformas e do framework DORA. O contraste é o que motiva o design da Divinci. O outage da Atlassian de abril de 2022[1] levou doze horas por site porque o estado estava espalhado por múltiplos sistemas que precisavam ser coordenados de volta em acordo. O outage da Cloudflare de junho de 2022[2] levou quarenta e quatro minutos para reverter porque, nas próprias palavras deles, engenheiros pisavam nas reversões uns dos outros. Os guardrails de deployment canário do AWS SageMaker[4] documentam uma espera padrão de dez minutos para término antes que o rollback complete totalmente. O limiar de elite DORA[3] para recuperação de deployment falho é “menos de uma hora” — essa é a barra que uma organização de alta performance deve superar, não o teto.
Doze segundos também não é um número mágico. É o tempo necessário para a camada de roteamento drenar requests em voo, trocar o manifesto ativo e confirmar o novo estado entre regiões. A parte lenta é a drenagem em voo. Não há caminho mais rápido que não derrube respostas no meio da geração.
O que isto é, que outras ferramentas de release de LLM não são
Pesquisamos doze outras ferramentas em 2026 antes de construir esta — LangSmith Deployment, W&B Models, MLflow, SageMaker Deployment Guardrails, Vertex AI Endpoints, Seldon Core, BentoCloud, KServe, Humanloop, Braintrust, Patronus AI, Arize Phoenix. Elas se agrupam em dois campos que não chegam a se encontrar.
O campo eval-CI — Braintrust, Humanloop, Patronus — gateia merges de PR com pontuações de eval offline. Eles nunca tocam o serviço em execução. Quando o modelo está em produção e a qualidade cai, eles alertam; alguém mais tem que fazer rollback.
O campo serving-canary — SageMaker Deployment Guardrails, KServe, Vertex AI, BentoCloud, Seldon Core — divide tráfego e faz auto-rollback. Mas cada um deles dispara em métricas de infraestrutura: latência p99, taxa de erro, alarmes CloudWatch. Nenhum deles faz auto-rollback em uma regressão de qualidade. Não podem, porque não têm um juiz rodando na saída de produção.
A costura entre “passou na eval no merge do PR” e “canário ao vivo pontuado nas jornadas de usuário com as quais realmente nos importamos” é uma transição manual que toda equipe atualmente tem que cruzar sozinha. O post de blog menciona isso como o modo dominante de falha em 2026[6]. Nós fechamos essa costura. Especificamente:
- O gate é fatiado. ρ de Spearman por domínio contra um avaliador ancorado em humano, não uma única pontuação global. A cegueira a slices é o que todo outro gate tem.
- O canário observa qualidade de saída, não só p95. Replay contínuo de traços através do candidato, pontuado pelo mesmo juiz que alimentou o gate. Esta é a costura faltante.
- Cada decisão emite um recibo de release. Encadeado por hash, externamente ancorável, no formato JSON-com-SHA-256 que respalda nossas páginas de compliance. Para modelos open-weights — Gemma, Qwen, Llama, Mistral, GPT-OSS — o recibo embute uma atestação de pesos vIndex para que auditores possam provar quais eram de fato os pesos vivos. Para backings de APIs fechadas, o recibo cobre a cadeia de decisão, mas não reivindica proveniência de pesos, porque o provedor não expõe os pesos. De qualquer forma, auditores recebem provas do que é de fato provável, não apenas logs.
É isso. Canário genérico, registro de versão, rollback por métrica de infra — isso é commodity. Não escrevemos um canário genérico.
O que isto não resolve
Três limitações honestas:
O gate é tão bom quanto o dataset. Uma suíte scored-QA que não cobre o domínio que o cliente realmente usa não vai pegar regressões nesse domínio. Vimos isso duas vezes. Nas duas vezes, o primeiro movimento do cliente foi enviar uma nova suíte scored-QA, não trocar o modelo. Esse é o movimento correto.
O rollback assume que o release anterior era bom. Se uma regressão está viva por três releases e ninguém percebeu, fazer rollback de um release apenas te compra um modelo um pouco menos ruim. A trilha de auditoria ajuda aqui — você pode fazer rollback para qualquer manifesto anterior por SHA, não apenas N-1.
Releases de cold-start contornam o canário. Um modelo novinho em folha sem tráfego de produção para comparar não pode ser canariado de forma significativa. Forçamos um shadow deployment de 24 horas em vez disso, que observa saídas sem servi-las. É mais lento e menos conveniente. É também a única resposta honesta.
A menor versão disto que você pode rodar
Se você quer montar algo assim sem usar a Divinci, a versão mínima viável é aproximadamente:
- Um registro que armazena modelo + prompt + roteamento + dataset como um único artefato imutável, endereçado por hash de conteúdo
- Um juiz calibrado contra um painel ancorado em humano via ρ de Spearman — e uma decisão de gate que consulta pontuações por slice, não apenas o agregado
- Um divisor de tráfego que segura em checkpoints e consulta um monitor de qualidade com limite de frescor — onde o monitor faz replay de traços recentes de produção através do candidato, não apenas amostra sintéticos
- Uma camada de roteamento cujo estado possa ser trocado atomicamente — incluindo o template de prompt, não apenas os pesos
- Um audit log que emite um recibo encadeado por hash, externamente ancorável, para cada decisão de release — mais um embed de atestação de pesos quando o modelo é open-weights, já que releases de API fechada fisicamente não podem ser atestados no nível dos pesos
A maioria das equipes já tem (1) e (3). As partes dolorosas são (2), (4) e (5). A razão pela qual a Divinci existe é que construímos todas as cinco para nós mesmos primeiro, depois percebemos que todos os outros também iam precisar delas.
Se você quiser pular a construção, a referência da API está aqui, e os endpoints de release na seção “Release Management” são a superfície inteira deste pipeline. O lado de compliance — como esses recibos vIndex parecem e como mapeiam para o EU AI Act, Artigo 17 do GDPR, HIPAA e NIST AI RMF — está na página de compliance. Todo comando neste post é um endpoint real.
Referências
- Atlassian — Post-Incident Review: April 2022 Outage. Do writeup: "The accelerated Restoration 2 approach took approximately 12 hours to restore a site." A restauração completa de 883 sites de clientes levou 14 dias. O estado espalhado por infraestrutura, backups e validação por site empurra o número por site para horas em vez de minutos.
- Cloudflare — Cloudflare outage on June 21, 2022. Linha do tempo citada literalmente no post: "06:58: Root cause found and understood. Work begins to revert the problematic change… 07:42: The last of the reverts has been completed." Quarenta e quatro minutos do "sabemos o que reverter" ao "a reversão está feita", em parte porque os engenheiros estavam pisando nas reversões uns dos outros.
- DORA — Software delivery performance metrics. O limiar elite-performer de "failed deployment recovery time" é documentado como menos de uma hora. Low performers medem em semanas-a-meses nos relatórios históricos da DORA.
- AWS SageMaker — Use canary traffic shifting e a página acompanhante Auto-Rollback Configuration and Monitoring. O exemplo de
TerminationWaitInSecondsé 600 (dez minutos);MaximumExecutionTimeoutInSecondsé limitado a 1800 (trinta minutos). O rollback dispara dentro da janela de baking quando um alarme dispara: "If any of the alarms trip during the baking period, then SageMaker AI initiates a rollback and all traffic returns to the blue fleet." - Divinci AI — flip de roteamento atômico via manifesto de release. Doze segundos é o tempo de drenagem em voo em um serviço de ~100 réplicas; a troca do manifesto em si é sub-segundo. O número é do nosso próprio serviço, não de um benchmark; a arquitetura que torna isso possível é o manifesto agrupado descrito acima (Estágio 1 — Registrar).
- Tianpan — The Semver Lie: how an LLM minor update breaks production (April 2026). O writeup nomeia o padrão de falha diretamente: "passed code review, deployed without eval gates, hit production without per-user A/B, and triggered no automatic rollback." Um post acompanhante — LLM postmortem template — fields SRE missed — enumera os campos de slice / jornada / por-usuário que os postmortems atuais sistematicamente omitem.
Uma nota sobre o que não está neste gráfico. O tempo de kubectl rollout undo do Kubernetes é governado pelas suas configurações de maxSurge / maxUnavailable e pelo warm-up dos pods, não pelo comando em si, e não conseguimos encontrar uma fonte primária publicando um número medido da forma como as quatro fontes acima fazem — então deixamos de fora em vez de preencher com uma estimativa.
Próximo nesta série: 10 falhas de release CI/CD que pegamos em LMs customizados, e qual estágio do pipeline pega cada uma. Três das dez são regressões por slice que um gate agregado teria enviado. Duas a mais são quedas silenciosas de qualidade que um canário por métrica de infra teria promovido. O resto são o tipo de modo de falha que todo pipeline de release deveria pegar — listamos porque vale dizer em voz alta quais um pipeline com gate agregado, de fato, pega por conta própria.
Ready to Build Your Custom AI Solution?
Discover how Divinci AI can help you implement RAG systems, automate quality assurance, and streamline your AI development process.
Get Started Today