
Notities uit de releasecyclus — Deel I
De eerste keer dat we een LLM door een normale CI/CD-pipeline probeerden te releasen, werd de build groen, slaagde de deploy en begon de klantenservice binnen zeven minuten tickets te openen.
Er was niets “stuk.” Alle 4.200 integratietesten slaagden. De latency was onveranderd. De 200 OK-rate bleef stabiel. Maar bij een specifieke klasse juridische vragen was het nieuwe model stilletjes gaan hedgen — het weigerde een antwoord te geven dat de vorige versie wel correct had beantwoord. Geen enkele test ving het op, omdat we die nog niet hadden geschreven.
We rolden terug, en de rollback zelf was een gebeurtenis. Het modelartefact stond op drie plekken, de prompt template stond op een vierde, de routing rules stonden op een vijfde, en niets wist iets van iets anders. Het kostte iets meer dan twee uur om terug te keren naar de vorige goede staat. De klanten die tijdens dat venster een hedge geserveerd kregen, waren niet onder de indruk.
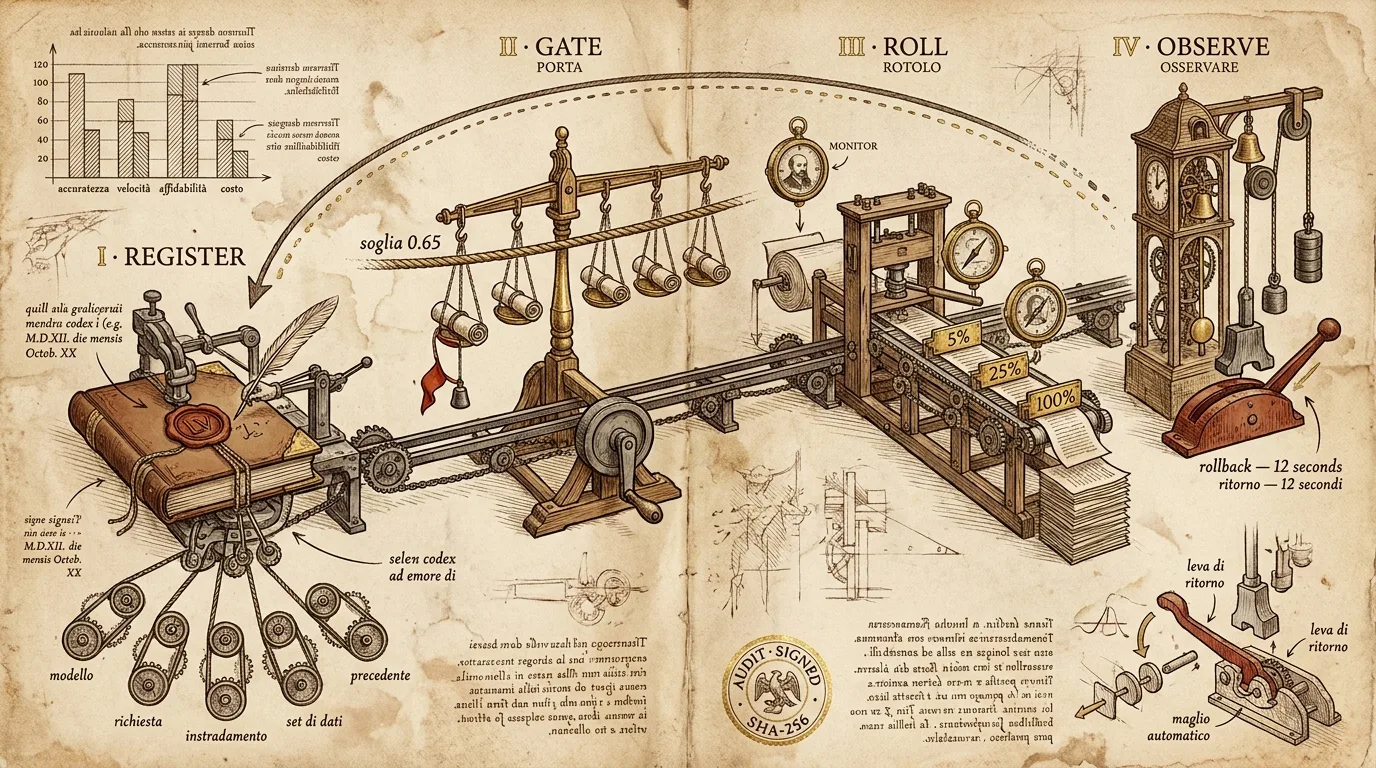
Die storing is de reden dat deze pipeline bestaat. Wat volgt is de pipeline die we daadwerkelijk voor onze eigen releases gebruiken, en die we via de Divinci API beschikbaar maken voor klanten die de hunne releasen. Hij heeft vier fases — register, gate, roll, observe — en elke stap heeft een rollbackpad dat niet afhankelijk is van een wakker mens.
De vier fases

De fases zijn bewust rigide. Elke release gaat in deze volgorde door elke fase. Een “hotfix”-pad dat evaluatie overslaat bestaat niet — dat hebben we één keer geprobeerd.
Fase 1 — Register
Een release is geen modelgewichtenbestand. Een release is een onveranderlijk manifest dat het volgende bundelt:
- Het modelartefact (HF-repo + commit-SHA, of een vIndex-patch)
- De prompt template (elke variabele, elk system message)
- De routing rules (welke traffic class landt op welke versie)
- De datasetversie die werd gebruikt om de gate-drempels te berekenen
- De SHA van de vorige release, zodat rollback ondubbelzinnig is
curl -X POST https://api.divinci.ai/v1/releases \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{
"model_ref": "Divinci-AI/gemma-4-e2b@a7c91f",
"prompt_template_ref": "templates/legal-qa@v14",
"routing": { "domain": "legal" },
"dataset_version": "scored-qa-medical-v3",
"previous_release": "rel_8f72b1"
}'
# → { "release_id": "rel_a01c66", "manifest_sha256": "9abaeaf6..." }De manifest-SHA is de enige handle die iemand in de pipeline ooit gebruikt. Als twee mensen deployen wat ze denken dat dezelfde release is en de SHA’s verschillen, wijst de pipeline de deploy af. Met deze regel hebben we inmiddels twee bugs gevangen.
Fase 2 — Gate
De gate is het onderdeel dat de meeste CI-pipelines verkeerd doen. Lighthouse-achtige heuristieken — perplexity, BLEU, ROUGE — laten een regressie door als die geconcentreerd is in één domein. Aggregaatscores spoelen het weg.
De gate van Divinci draait de scored-QA-suite waarmee het release-manifest is geregistreerd en past een Spearman-drempel per categorie toe:

De release in het diagram hierboven zou een aggregaatgate passeren (gemiddelde 0,64 is “goed genoeg”). Hij faalt op de gate van Divinci omdat IP licensing crasht van een eerdere 0,68 naar 0,41 — precies het soort gelokaliseerde regressie dat een notebook nooit opvangt.
We hebben slice-aware gating niet voor de lol uitgevonden. Het is exact de gemiste failure mode in de huidige lichting LLM-postmortems. Tianpan’s “The Semver Lie”-verslag[6] beschrijft een promptwijziging die “code review passeerde, werd gedeployed zonder eval-gates, productie raakte zonder per-user A/B en geen automatische rollback triggerde.” Wat dat incident catastrofaal maakte in plaats van louter vervelend was dat de regressie geconcentreerd was in één slice — één enkele user-journey-klasse — terwijl het aggregaat overeind bleef. Elke LLM-releasetool die we in 2026 hebben onderzocht, gate’t ofwel op één globale score, ofwel helemaal niet. Geen enkele slice’t de gate.
Een gate failure is geen zachte waarschuwing. Het release_id wordt gemarkeerd als gate_fail, het manifest wordt gearchiveerd en geen deploy-commando accepteert het. Cold-start releases — een gloednieuw model zonder historische Spearman om mee te vergelijken — gaan eenmalig door een --force-gate-override-pad dat een schriftelijke onderbouwing vereist; de onderbouwing, het user-ID en een gate_override_sha256 belanden direct in het audit trail. Override bestaat omdat er legitieme situaties voor zijn; het audit trail bestaat omdat de toekomstige jij die onderbouwing moet kunnen teruglezen.
Fase 3 — Roll
Een canary bij Divinci betekent drie checkpoints: 5%, 25%, 100%. Bij elk checkpoint wacht de pipeline op ofwel de geconfigureerde dwell time, ofwel het geconfigureerde request count, afhankelijk van wat later is. Default is 4 minuten / 1.000 requests bij 5%, 15 minuten / 10.000 requests bij 25%.
Bij elk checkpoint moeten drie monitors standhouden:
- p95 latency binnen 1,2× de p95 van de vorige release
- 5xx rate binnen 1,5× de rate van de vorige release
- Output-quality monitor: een continue replay van recente productietraces door de kandidaat-release, gescoord door dezelfde gekalibreerde judge die ook fase 2 aandreef
De derde is degene die geen enkele andere release pipeline levert. SageMaker, KServe, BentoML, Vertex AI — allemaal bewaken ze latency en error rate. Geen enkele scoort de outputs van de kandidaat tegen de daadwerkelijke vragen die productie op dit moment stelt. De kandidaat krijgt dezelfde prompts die de actieve release zojuist kreeg, draait ze op een 5%-mirror, en wij meten de Spearman ρ van de antwoorden van de kandidaat tegen de gekalibreerde grader. De 5xx rate kan schoon blijven terwijl het model stilletjes hedgt, weigert of hallucineert. We hebben dit zien gebeuren. De trace-replay-monitor is wat het opvangt.
De replay set is begrensd — we cappen op 50 recente traces per slice per checkpoint, zodat de kosten voorspelbaar zijn. Grading kost ongeveer 90 seconden bij 5% traffic. Trager dan een platte percentage-canary, sneller dan wachten tot een klant een ticket opent.
# Het roll-commando is fire-and-forget. De pipeline houdt zichzelf vast.
curl -X POST https://api.divinci.ai/v1/releases/rel_a01c66/roll \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{ "strategy": "canary", "dwell_5pct_seconds": 240, "dwell_25pct_seconds": 900 }'
# → { "rollout_id": "rol_b3e2", "next_checkpoint_at": "2026-05-26T09:04:00Z" }Fase 4 — Observeren, rollback en het bewijs
Dit is de fase die het bestaansrecht van de pipeline verdient.
De observer draait continu na het afronden van de rollout. Hij berekent per minuut een output-quality-score op een rollend 5%-trace-replay-sample. Als de score onder de rollback-drempel valt (default: 0,85 van de gate-drempel, dus 0,55 als de gate 0,65 was) gedurende drie opeenvolgende minuten, vuurt de rollback automatisch. Geen page, geen mens, geen discussie.
De rollback zelf is één enkele instructie: zet routing terug op previous_release uit het manifest. Omdat de vorige release een volledig gebundeld manifest was, flipt elk component — weights, prompt, routing, dataset — atomisch mee.
Daarna vuurt het bewijs.
Elke release-beslissing — register, gate-pass, gate-fail, gate-override, checkpoint-promote, checkpoint-hold, auto-rollback, manual-rollback — produceert een release-bewijs (release receipt): een JSON-met-SHA-256-artefact, hash-chained aan het vorige bewijs voor deze klant en aan het vorige bewijs voor deze release, extern verankerd op een door de klant geconfigureerd schema.
Wanneer de release gedragen wordt door een open-weights model — Gemma, Qwen, Llama, Mistral, GPT-OSS, alles waarvan de gewichten adresseerbaar en bewerkbaar zijn — bedt het bewijs een vIndex-attestation in: een cryptografisch bewijs dat de actieve gewichten op het moment van beslissing de gewichten zijn die het manifest registreerde. Dat is het pad dat de zwaardere compliance-eisen afdekt (GDPR Artikel 17 right-to-erasure, EU AI Act-provenance), omdat je niet alleen kunt bewijzen wat is gedeployed, maar ook dat de onderliggende gewichten zijn wat ze beweren te zijn.
Wanneer de release gedragen wordt door een closed-weights model — OpenAI, Anthropic, Google, alles wat alleen via een ondoorzichtige API wordt geleverd — dekt het bewijs nog steeds de beslissingsketen (welk manifest, welk gate-resultaat, welke monitor-meting, welke gebruiker triggerde welke actie), maar kan het de onderliggende gewichten niet attesteren, omdat we ze niet kunnen zien. Dat is geen beperking van de pipeline; het is een beperking van wat verifieerbaar is wanneer de provider de gewichten niet blootstelt. Auditors die om dat onderscheid geven, krijgen het eerlijke antwoord rechtstreeks in het bewijs zelf.
Hoe dan ook: auditors krijgen vandaag logs. Met deze pipeline krijgen ze bewijzen van alles wat daadwerkelijk te bewijzen is. We zagen niemand anders in de markt dit leveren. We verwachten dat ze het gaan doen — de tijdslijnen van de EU AI Act maken het uiteindelijk onvermijdelijk. Wij hebben gekozen het nu te leveren.
Dit zijn niet onze cijfers — het zijn gepubliceerde primaire-broncijfers uit echte postmortems, platformdocumentatie en het DORA-framework. Het contrast is wat het ontwerp van Divinci motiveert. De Atlassian-storing van april 2022[1] nam twaalf uur per site, omdat de state verspreid was over meerdere systemen die weer met elkaar in overeenstemming moesten worden gecoördineerd. De Cloudflare-storing van juni 2022[2] nam vierenveertig minuten om terug te draaien, omdat — in hun eigen woorden — engineers over elkaars reverts heen liepen. AWS SageMaker’s canary deployment guardrails[4] documenteren een default termination wait van tien minuten voordat de rollback volledig is afgerond. De DORA[3]-elite-drempel voor herstel van mislukte deployments is “onder één uur” — dat is de lat die een high-performing organisatie geacht wordt te halen, niet het plafond.
Twaalf seconden is ook geen magisch getal. Het is de tijd die de routinglaag nodig heeft om in-flight requests te draineren, het actieve manifest te swappen en de nieuwe state te ack’en over regio’s heen. Het trage deel is de in-flight drain. Er is geen sneller pad dat geen responses midden in de generatie laat vallen.
Wat dit is, waar andere LLM-releasetools dat niet zijn
We hebben in 2026 twaalf andere tools onderzocht voordat we dit bouwden — LangSmith Deployment, W&B Models, MLflow, SageMaker Deployment Guardrails, Vertex AI Endpoints, Seldon Core, BentoCloud, KServe, Humanloop, Braintrust, Patronus AI, Arize Phoenix. Ze clusteren in twee kampen die elkaar niet helemaal raken.
Het eval-CI-kamp — Braintrust, Humanloop, Patronus — gate’t PR-merges op offline eval-scores. Ze raken de draaiende service nooit aan. Wanneer het model in productie is en de kwaliteit zakt, geven ze een alert; iemand anders moet de rollback uitvoeren.
Het serving-canary-kamp — SageMaker Deployment Guardrails, KServe, Vertex AI, BentoCloud, Seldon Core — splitst traffic en doet auto-rollback. Maar elk van hen triggert op infrastructure-metrics: p99 latency, error rate, CloudWatch alarms. Geen enkele rollt automatisch terug op een kwaliteitsregressie. Dat kunnen ze niet, omdat ze geen judge draaien op productie-output.
De naad tussen “geslaagd voor eval bij PR-merge” en “live canary, gescoord op de user journeys die we echt belangrijk vinden” is een handmatige overdracht die elk team momenteel zelf moet overbruggen. De blogpost wijst dat aan als de dominante 2026-failuremode[6]. Wij hebben hem dichtgemaakt. Specifiek:
- De gate is gesliced. Spearman ρ per domein tegen een human-anchored grader, geen enkele globale score. Slice-blindheid is wat elke andere gate heeft.
- De canary bewaakt outputkwaliteit, niet alleen p95. Continue trace-replay door de kandidaat, gescoord door dezelfde judge die de gate aandreef. Dit is de ontbrekende naad.
- Elke beslissing produceert een release-bewijs. Hash-chained, extern verankerbaar, in het JSON-met-SHA-256-formaat dat onze compliancepagina’s onderbouwt. Voor open-weights-modelbackings — Gemma, Qwen, Llama, Mistral, GPT-OSS — bedt het bewijs een vIndex-weight-attestation in, zodat auditors kunnen bewijzen wat de live gewichten daadwerkelijk waren. Voor closed-API-backings dekt het bewijs de beslissingsketen maar claimt het geen weight-provenance, omdat de provider geen gewichten blootstelt. Hoe dan ook: auditors krijgen bewijzen van wat daadwerkelijk te bewijzen is, niet alleen logs.
Dat is alles. Generieke canary, version registry, infra-metric rollback — dat is commodity. Wij hebben geen generieke canary geschreven.
Wat dit niet oplost
Drie eerlijke beperkingen:
De gate is alleen zo goed als de dataset. Een scored-QA-suite die het domein dat een klant daadwerkelijk gebruikt niet dekt, zal regressies in dat domein niet opvangen. We hebben dit twee keer gezien. Beide keren was de eerste actie van de klant om een nieuwe scored-QA-suite te releasen, niet om het model te veranderen. Dat is de juiste actie.
De rollback gaat ervan uit dat de vorige release goed was. Als een regressie al drie releases live staat en niemand het heeft gemerkt, koop je met één release terugrollen alleen een iets minder slecht model. Het audit trail helpt hier — je kunt terugrollen naar elk eerder manifest via SHA, niet alleen N-1.
Cold-start releases omzeilen de canary. Een gloednieuw model zonder productietraffic om mee te vergelijken kan niet zinvol gecanaryed worden. We forceren in plaats daarvan een shadow deployment van 24 uur, die outputs observeert zonder ze te serveren. Het is trager en minder gemakkelijk. Het is ook het enige eerlijke antwoord.
De kleinste versie hiervan die je kunt draaien
Als je iets vergelijkbaars wilt opzetten zonder Divinci te gebruiken, is de minimaal werkbare versie ongeveer:
- Een registry die model + prompt + routing + dataset opslaat als één onveranderlijk artefact, geadresseerd via content hash
- Een judge die gekalibreerd is tegen een human-anchored panel via Spearman ρ — en een gate-beslissing die per-slice-scores raadpleegt, niet alleen het aggregaat
- Een traffic splitter die op checkpoints stopt en een vers-begrensde quality monitor raadpleegt — waarbij de monitor recente productietraces opnieuw afspeelt door de kandidaat, niet alleen synthetische sampelt
- Een routinglaag waarvan de state atomisch geswapt kan worden — inclusief de prompt template, niet alleen de gewichten
- Een audit log dat een hash-chained, extern-verankerbaar bewijs produceert voor elke release-beslissing — plus een weight-attestation-embed wanneer het model open-weights is, omdat closed-API-releases op weight-niveau fysiek niet geattesteerd kunnen worden
De meeste teams hebben (1) en (3) al. De pijnlijke stukken zijn (2), (4) en (5). De reden dat Divinci bestaat, is dat we deze vijf eerst voor onszelf hebben gebouwd en toen beseften dat iedereen ze ook nodig zou krijgen.
Als je de bouw wilt overslaan: de API-referentie staat hier, en de release-endpoints in het onderdeel “Release Management” vormen het volledige oppervlak van deze pipeline. De compliancekant — hoe die vIndex-bewijzen eruitzien en hoe ze afbeelden op de EU AI Act, GDPR Artikel 17, HIPAA en NIST AI RMF — staat op de compliancepagina. Elk commando in deze post is een echt endpoint.
Referenties
- Atlassian — Post-Incident Review: April 2022 Outage. Uit het verslag: "The accelerated Restoration 2 approach took approximately 12 hours to restore a site." Volledig herstel van 883 klant-sites duurde 14 dagen. State verspreid over infrastructuur, backups en per-site validatie drijft het per-site-getal de uren in in plaats van minuten.
- Cloudflare — Cloudflare outage on June 21, 2022. Tijdlijn, verbatim geciteerd in het bericht: "06:58: Root cause found and understood. Work begins to revert the problematic change… 07:42: The last of the reverts has been completed." Vierenveertig minuten van "we weten wat we moeten terugdraaien" naar "het terugdraaien is klaar", deels doordat engineers over elkaars reverts heen stapten.
- DORA — Software delivery performance metrics. De drempel voor "failed deployment recovery time" voor elite performers is gedocumenteerd als onder één uur. Low performers meten in weken-tot-maanden in DORA's historische rapporten.
- AWS SageMaker — Use canary traffic shifting en de bijbehorende Auto-Rollback Configuration and Monitoring-pagina. De voorbeeldwaarde voor
TerminationWaitInSecondsis 600 (tien minuten);MaximumExecutionTimeoutInSecondsis begrensd op 1800 (dertig minuten). Rollback vuurt binnen het baking-window zodra een alarm afgaat: "If any of the alarms trip during the baking period, then SageMaker AI initiates a rollback and all traffic returns to the blue fleet." - Divinci AI — atomische routing-flip via release-manifest. Twaalf seconden is de in-flight drain time op een service met ~100 replica's; de manifest-swap zelf is sub-seconde. Het getal komt uit onze eigen service, niet uit een benchmark; de architectuur die het mogelijk maakt, is het gebundelde manifest beschreven hierboven (Fase 1 — Register).
- Tianpan — The Semver Lie: how an LLM minor update breaks production (april 2026). Het verslag benoemt het failure pattern direct: "passed code review, deployed without eval gates, hit production without per-user A/B, and triggered no automatic rollback." Een bijbehorende post — LLM postmortem template — fields SRE missed — somt de slice / journey / per-user-velden op die huidige postmortems systematisch weglaten.
Een opmerking over wat niet op dit diagram staat. De tijd voor Kubernetes kubectl rollout undo wordt bepaald door je maxSurge / maxUnavailable-instellingen en pod-warm-up, niet door het commando zelf, en we konden geen primaire bron vinden die een gemeten getal publiceert op dezelfde manier als de vier bronnen hierboven — dus we hebben het weggelaten in plaats van het in te vullen met een schatting.
Volgende in deze serie: 10 CI/CD-releasefouten die we in custom LM’s hebben gevangen, en welke fase van de pipeline elk ervan opvangt. Drie van de tien zijn slice-bewuste regressies die een aggregaatgate zou hebben gereleased. Twee andere zijn stille kwaliteitsdips die een infra-metric-canary zou hebben gepromoveerd. De rest is het soort failure mode dat elke releasepipeline geacht wordt op te vangen — we noemen ze omdat het waard is hardop te zeggen welke een aggregaat-gated pipeline daadwerkelijk wel zelf opvangt.
Ready to Build Your Custom AI Solution?
Discover how Divinci AI can help you implement RAG systems, automate quality assurance, and streamline your AI development process.
Get Started Today