
Appunti dal ciclo di rilascio — Parte I
La prima volta che abbiamo provato a spedire un LLM attraverso una normale pipeline CI/CD, la build è diventata verde, il deploy ha avuto successo e il supporto clienti ha iniziato ad aprire ticket entro sette minuti.
Niente si era “rotto”. Tutti i 4.200 test di integrazione erano passati. La latenza era invariata. Il tasso di 200 OK era stabile. Ma su una specifica classe di domande di dominio legale, il nuovo modello aveva iniziato silenziosamente a tergiversare — rifiutandosi di impegnarsi su una risposta che la versione precedente aveva dato correttamente. Nessun test l’aveva catturato perché non ne avevamo ancora scritto uno.
Abbiamo fatto rollback, e il rollback stesso è stato un evento. L’artefatto del modello viveva in tre posti, il template del prompt viveva in un quarto, le regole di routing vivevano in un quinto, e niente sapeva niente di niente. Ci sono volute poco più di due ore per tornare allo stato buono precedente. I clienti che erano stati serviti con una risposta evasiva in quella finestra non sono rimasti contenti.
Quel disservizio è il motivo per cui questa pipeline esiste. Quello che segue è quella effettiva attraverso cui spediamo i nostri rilasci, e quella che esponiamo tramite l’API Divinci ai clienti che spediscono i loro. Ha quattro stadi — register, gate, roll, observe — e ogni passo ha un percorso di rollback che non dipende dal fatto che un essere umano sia sveglio.
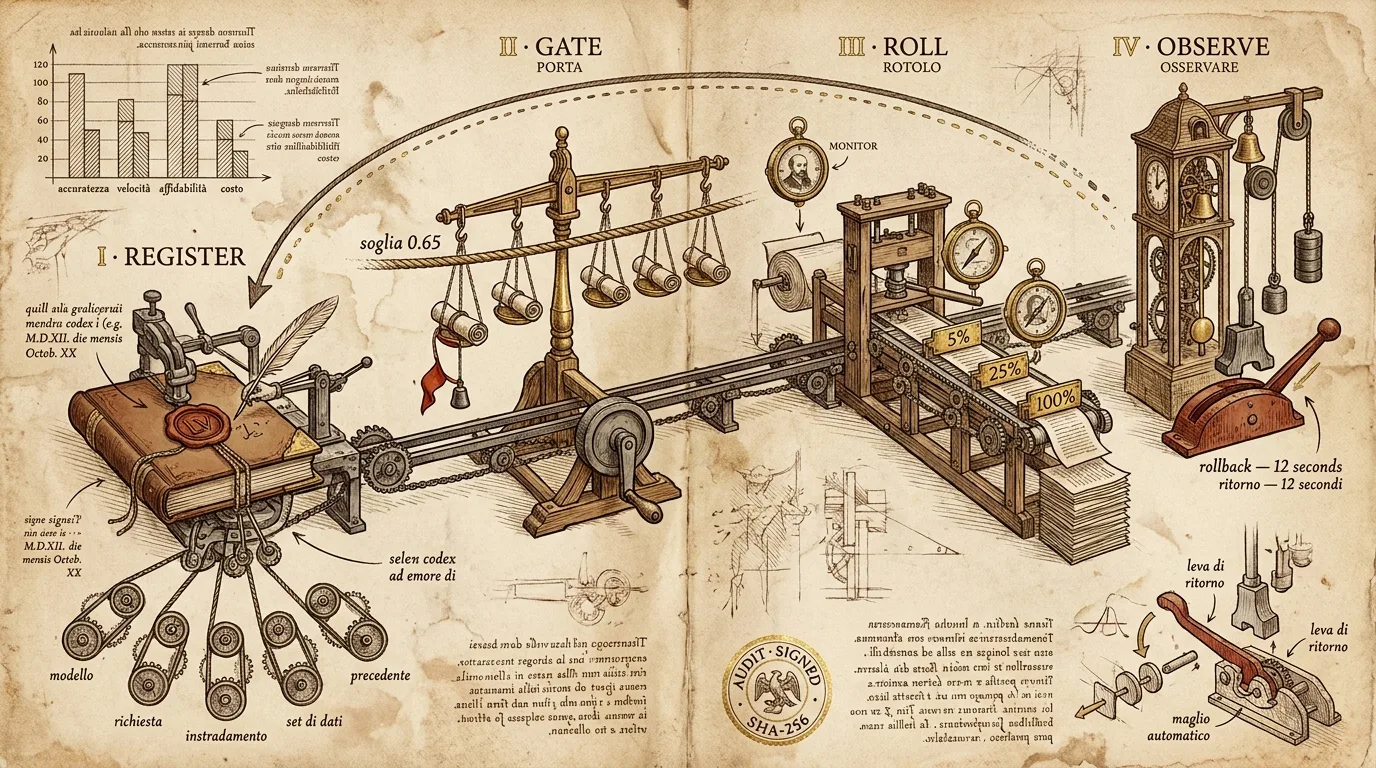
I quattro stadi

Gli stadi sono intenzionalmente rigidi. Ogni rilascio passa attraverso ogni stadio in questo ordine. Un percorso di “hotfix” che salta la valutazione non esiste — l’abbiamo provato una volta.
Stadio 1 — Register
Un rilascio non è un file di pesi del modello. Un rilascio è un manifesto immutabile che raggruppa:
- L’artefatto del modello (repo HF + SHA del commit, o una patch vIndex)
- Il template del prompt (ogni variabile, ogni messaggio di sistema)
- Le regole di routing (quale classe di traffico atterra su quale versione)
- La versione del dataset usata per calcolare le soglie del gate
- Lo SHA del rilascio precedente, in modo che il rollback sia inequivocabile
curl -X POST https://api.divinci.ai/v1/releases \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{
"model_ref": "Divinci-AI/gemma-4-e2b@a7c91f",
"prompt_template_ref": "templates/legal-qa@v14",
"routing": { "domain": "legal" },
"dataset_version": "scored-qa-medical-v3",
"previous_release": "rel_8f72b1"
}'
# → { "release_id": "rel_a01c66", "manifest_sha256": "9abaeaf6..." }Lo SHA del manifesto è l’unico handle che chiunque nella pipeline usa. Se due persone fanno il deploy di quello che pensano sia lo stesso rilascio e gli SHA differiscono, la pipeline rifiuta il deploy. Abbiamo già catturato due bug con questa regola.
Stadio 2 — Gate
Il gate è la parte che la maggior parte delle pipeline CI sbaglia. Le euristiche in stile Lighthouse — perplessità, BLEU, ROUGE — lasceranno passare una regressione se la regressione è concentrata in un dominio. I punteggi aggregati la diluiscono.
Il gate di Divinci esegue la suite scored-QA con cui è stato registrato il manifesto del rilascio, e applica una soglia Spearman per categoria:

Il rilascio nel grafico sopra passerebbe un gate aggregato (la media di 0,64 è “abbastanza vicina”). Fallisce il gate di Divinci perché le licenze IP crollano da un precedente 0,68 a 0,41 — esattamente il tipo di regressione localizzata che un notebook non cattura mai.
Non abbiamo inventato il gating per fetta per divertimento. È la modalità di fallimento direttamente nominata nella generazione attuale dei postmortem LLM. Il post “The Semver Lie” di Tianpan[6] descrive un cambio di prompt che “ha passato la code review, è stato deployato senza eval gate, ha colpito la produzione senza A/B per utente e non ha innescato alcun rollback automatico.” La cosa che ha reso quell’incidente catastrofico invece che semplicemente fastidioso è che la regressione era concentrata in una fetta — una singola classe di user journey — mentre l’aggregato teneva. Ogni strumento di rilascio LLM che abbiamo passato in rassegna nel 2026 o fa gate su un singolo punteggio globale, o non fa gate affatto. Nessuno di loro affetta il gate.
Un fallimento del gate non è un avviso soft. Il release_id è marcato gate_fail, il manifesto è archiviato, e nessun comando di deploy lo accetterà. I rilasci a freddo — un modello nuovo di zecca senza Spearman storica con cui confrontarsi — passano attraverso un percorso una tantum --force-gate-override che richiede una motivazione scritta; la motivazione, l’ID utente e un gate_override_sha256 finiscono direttamente nell’audit trail. L’override esiste perché ci sono situazioni legittime per esso; l’audit trail esiste perché il te-del-futuro ha bisogno di leggere la motivazione.
Stadio 3 — Roll
Un canary in Divinci significa tre checkpoint: 5%, 25%, 100%. A ogni checkpoint, la pipeline si ferma o per il tempo di permanenza configurato o per il conteggio di richieste configurato, qualunque sia più tardi. Il default è 4 minuti / 1.000 richieste al 5%, 15 minuti / 10.000 richieste al 25%.
A ogni checkpoint, tre monitor devono tenere:
- Latenza p95 entro 1,2× il p95 del rilascio precedente
- Tasso di 5xx entro 1,5× il tasso del rilascio precedente
- Monitor di qualità dell’output: un replay continuo di tracce di produzione recenti attraverso il rilascio candidato, valutato dallo stesso giudice calibrato che ha alimentato lo Stadio 2
Il terzo è quello che nessun’altra pipeline di rilascio offre. SageMaker, KServe, BentoML, Vertex AI — tutti loro osservano latenza e tasso di errore. Nessuno di loro valuta gli output del candidato contro le domande effettive che la produzione sta facendo proprio ora. Il candidato riceve gli stessi prompt che il rilascio attivo ha appena ricevuto, li esegue su un mirror al 5%, e misuriamo la Spearman ρ delle risposte del candidato contro il grader calibrato. Il tasso di 5xx può restare pulito mentre il modello silenziosamente tergiversa, rifiuta o allucina. L’abbiamo visto accadere. Il monitor di replay delle tracce è ciò che lo cattura.
L’insieme di replay è limitato — facciamo cap a 50 tracce recenti per fetta per checkpoint in modo che il costo sia prevedibile. La valutazione richiede circa 90 secondi al 5% di traffico. Più lento di un canary a percentuale piatta, più veloce dell’attendere che un cliente apra un ticket.
# Il comando roll è fire-and-forget. La pipeline si tiene da sola.
curl -X POST https://api.divinci.ai/v1/releases/rel_a01c66/roll \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{ "strategy": "canary", "dwell_5pct_seconds": 240, "dwell_25pct_seconds": 900 }'
# → { "rollout_id": "rol_b3e2", "next_checkpoint_at": "2026-05-26T09:04:00Z" }Stadio 4 — Osservare, rollback e la ricevuta
Questo è lo stadio che giustifica l’esistenza della pipeline.
L’osservatore gira continuamente dopo il completamento del rollout. Calcola un punteggio di qualità dell’output al minuto su un campione mobile di replay di tracce al 5%. Se il punteggio scende sotto la soglia di rollback (default: 0,85 della soglia del gate, quindi 0,55 se il gate era 0,65) per tre minuti consecutivi, il rollback parte automaticamente. Nessuna page, nessun umano, nessun dibattito.
Il rollback stesso è una singola istruzione: ripuntare il routing a previous_release dal manifesto. Poiché il rilascio precedente era un manifesto pienamente raggruppato, ogni componente — pesi, prompt, routing, dataset — si ribalta atomicamente.
Poi parte la ricevuta.
Ogni decisione di rilascio — register, gate-pass, gate-fail, gate-override, checkpoint-promote, checkpoint-hold, auto-rollback, manual-rollback — emette una ricevuta di rilascio: un artefatto JSON-con-SHA-256, concatenato in hash alla ricevuta precedente per questo cliente e alla ricevuta precedente per questo rilascio, ancorato esternamente con una cadenza che il cliente configura.
Quando il rilascio è basato su un modello open-weights — Gemma, Qwen, Llama, Mistral, GPT-OSS, qualsiasi cosa in cui i pesi siano indirizzabili ed editabili — la ricevuta integra una attestazione vIndex: una prova crittografica che i pesi attivi al momento della decisione sono i pesi che il manifesto ha registrato. Questo è il percorso che soddisfa le richieste di conformità più dure (diritto all’oblio dell’Articolo 17 GDPR, provenance dell’EU AI Act) perché puoi dimostrare non solo cosa è stato deployato ma che i pesi sottostanti sono quelli che dichiarano di essere.
Quando il rilascio è basato su un modello closed-weights — OpenAI, Anthropic, Google, qualsiasi cosa servita solo tramite un’API opaca — la ricevuta copre ancora la catena delle decisioni (quale manifesto, quale risultato del gate, quale lettura del monitor, quale utente ha innescato quale azione) ma non può attestare i pesi sottostanti, perché non possiamo vederli. Questo non è un limite della pipeline; è un limite di ciò che è verificabile quando il fornitore non espone i pesi. Gli auditor a cui importa quella distinzione ottengono la risposta veritiera nella ricevuta stessa.
In entrambi i casi, oggi gli auditor ottengono log. Con questa pipeline, ottengono prove di tutto ciò che è effettivamente dimostrabile. Non abbiamo visto nessun altro sul mercato spedire questo. Ci aspettiamo che lo facciano — le tempistiche dell’EU AI Act lo rendono prima o poi inevitabile. Noi abbiamo scelto di spedirlo ora.
Questi non sono i nostri numeri — sono numeri pubblicati da fonti primarie, da postmortem reali, dalla documentazione di piattaforma e dal framework DORA. Il contrasto è ciò che motiva il design di Divinci. Il disservizio di Atlassian dell’aprile 2022[1] ha richiesto dodici ore per sito perché lo stato era distribuito su più sistemi che dovevano essere coordinati per tornare in accordo. Il disservizio di Cloudflare del giugno 2022[2] ha richiesto quarantaquattro minuti per il revert perché, parole loro, gli ingegneri si calpestavano i revert a vicenda. I deployment guardrails canary di AWS SageMaker[4] documentano un’attesa di terminazione di default di dieci minuti prima che il rollback si completi totalmente. La soglia elite DORA[3] per il recupero da deploy fallito è “sotto un’ora” — questa è l’asticella che ci si aspetta che un’organizzazione ad alte prestazioni superi, non il soffitto.
Anche dodici secondi non è un numero magico. È il tempo richiesto al livello di routing per drenare le richieste in volo, scambiare il manifesto attivo e fare ack del nuovo stato attraverso le regioni. La parte lenta è il drain in volo. Non c’è un percorso più veloce che non scarti risposte a metà generazione.
Cos’è questo, e cosa non sono gli altri strumenti di rilascio LLM
Abbiamo passato in rassegna dodici altri strumenti nel 2026 prima di costruire questo — LangSmith Deployment, W&B Models, MLflow, SageMaker Deployment Guardrails, Vertex AI Endpoints, Seldon Core, BentoCloud, KServe, Humanloop, Braintrust, Patronus AI, Arize Phoenix. Si raggruppano in due campi che non si incontrano del tutto.
Il campo eval-CI — Braintrust, Humanloop, Patronus — fa gate sui merge delle PR usando punteggi di eval offline. Non tocca mai il servizio in esecuzione. Quando il modello è in produzione e la qualità cala, fanno alert; qualcun altro deve fare il rollback.
Il campo serving-canary — SageMaker Deployment Guardrails, KServe, Vertex AI, BentoCloud, Seldon Core — divide il traffico e fa auto-rollback. Ma ognuno di loro si attiva su metriche di infrastruttura: latenza p99, tasso di errore, allarmi CloudWatch. Nessuno di loro fa auto-rollback su una regressione di qualità. Non possono, perché non hanno un giudice in esecuzione sull’output di produzione.
La cucitura tra “ha passato l’eval al merge della PR” e “canary live valutato sui user journey che ci interessano davvero” è un passaggio manuale che ogni team attualmente deve colmare da sé. Il post sul blog la indica come la modalità di fallimento dominante del 2026[6]. Noi l’abbiamo chiusa. Specificamente:
- Il gate è affettato. Spearman ρ per dominio contro un grader ancorato all’umano, non un singolo punteggio globale. La cecità alle fette è ciò che ogni altro gate ha.
- Il canary osserva la qualità dell’output, non solo il p95. Replay continuo di tracce attraverso il candidato, valutato dallo stesso giudice che ha alimentato il gate. Questa è la cucitura mancante.
- Ogni decisione emette una ricevuta di rilascio. Concatenata in hash, ancorabile esternamente, nel formato JSON-con-SHA-256 che supporta le nostre pagine di conformità. Per i backing di modelli open-weights — Gemma, Qwen, Llama, Mistral, GPT-OSS — la ricevuta integra un’attestazione dei pesi vIndex in modo che gli auditor possano dimostrare quali fossero effettivamente i pesi attivi. Per i backing closed-API, la ricevuta copre la catena delle decisioni ma non rivendica la provenienza dei pesi, perché il fornitore non espone i pesi. In entrambi i casi, gli auditor ottengono prove di ciò che è effettivamente dimostrabile, non solo log.
Tutto qui. Canary generico, registro di versioni, rollback su metrica infrastrutturale — quelle sono commodity. Non abbiamo scritto un canary generico.
Cosa questo non risolve
Tre limitazioni oneste:
Il gate è buono solo quanto il dataset. Una suite scored-QA che non copre il dominio che un cliente effettivamente usa non catturerà regressioni in quel dominio. L’abbiamo visto due volte. Entrambe le volte la prima mossa del cliente è stata spedire una nuova suite scored-QA, non cambiare il modello. Quella è la mossa corretta.
Il rollback presume che il rilascio precedente fosse buono. Se una regressione è stata in produzione per tre rilasci e nessuno se n’è accorto, fare rollback di un rilascio ti compra solo un modello leggermente meno cattivo. L’audit trail aiuta qui — puoi fare rollback a qualsiasi manifesto precedente per SHA, non solo a N-1.
I rilasci a freddo bypassano il canary. Un modello nuovo di zecca senza traffico di produzione con cui confrontarsi non può essere canariato in modo significativo. Forziamo invece un deployment in shadow di 24 ore, che osserva gli output senza servirli. È più lento e meno conveniente. È anche l’unica risposta onesta.
La versione più piccola di questo che puoi eseguire
Se vuoi tirare su qualcosa di simile senza usare Divinci, la versione minima vitale è grosso modo:
- Un registro che memorizza modello + prompt + routing + dataset come un singolo artefatto immutabile, indirizzato per hash di contenuto
- Un giudice calibrato contro un panel ancorato all’umano via Spearman ρ — e una decisione di gate che consulta punteggi per fetta, non solo l’aggregato
- Uno splitter di traffico che si ferma ai checkpoint e consulta un monitor di qualità limitato per freschezza — dove il monitor fa replay di tracce di produzione recenti attraverso il candidato, non solo campiona quelle sintetiche
- Un livello di routing il cui stato può essere scambiato atomicamente — incluso il template del prompt, non solo i pesi
- Un audit log che emette una ricevuta concatenata in hash e ancorabile esternamente per ogni decisione di rilascio — più un’attestazione dei pesi integrata quando il modello è open-weights, dato che i rilasci closed-API fisicamente non possono essere attestati a livello dei pesi
La maggior parte dei team ha già (1) e (3). Le parti dolorose sono (2), (4) e (5). Il motivo per cui Divinci esiste è che abbiamo costruito tutti e cinque prima per noi stessi, poi abbiamo capito che ne avrebbero avuto bisogno anche tutti gli altri.
Se vuoi saltare la costruzione, il riferimento API è qui, e gli endpoint di rilascio nella sezione “Release Management” sono l’intera superficie di questa pipeline. Il lato conformità — l’aspetto di quelle ricevute vIndex e come si mappano sull’EU AI Act, sull’Articolo 17 GDPR, su HIPAA e su NIST AI RMF — è sulla pagina di conformità. Ogni comando in questo post è un endpoint reale.
Riferimenti
- Atlassian — Post-Incident Review: April 2022 Outage. Dal report: "L'approccio accelerato Restoration 2 ha richiesto circa 12 ore per ripristinare un sito." Il ripristino completo di 883 siti cliente ha richiesto 14 giorni. Lo stato distribuito su infrastruttura, backup e validazione per sito spinge il numero per sito in ore piuttosto che in minuti.
- Cloudflare — Cloudflare outage on June 21, 2022. Timeline citata letteralmente nel post: "06:58: Causa principale individuata e compresa. Inizia il lavoro per fare revert del cambio problematico... 07:42: L'ultimo dei revert è stato completato." Quarantaquattro minuti da "sappiamo cosa fare revert" a "il revert è fatto", in parte perché gli ingegneri si calpestavano i revert a vicenda.
- DORA — Software delivery performance metrics. La soglia per elite-performer del "tempo di recupero da deploy fallito" è documentata come sotto un'ora. I low performer si misurano in settimane-mesi nei report storici di DORA.
- AWS SageMaker — Use canary traffic shifting e la pagina compagna Auto-Rollback Configuration and Monitoring. L'esempio di
TerminationWaitInSecondsè 600 (dieci minuti);MaximumExecutionTimeoutInSecondsè limitato a 1800 (trenta minuti). Il rollback parte all'interno della finestra di baking quando un allarme scatta: "Se uno qualsiasi degli allarmi scatta durante il periodo di baking, allora SageMaker AI avvia un rollback e tutto il traffico torna alla flotta blue." - Divinci AI — routing-flip atomico tramite manifesto di rilascio. Dodici secondi è il tempo di drain in volo su un servizio a circa 100 repliche; lo scambio del manifesto in sé è sub-secondo. Il numero viene dal nostro servizio, non da un benchmark; l'architettura che lo rende possibile è il manifesto raggruppato descritto sopra (Stadio 1 — Register).
- Tianpan — The Semver Lie: how an LLM minor update breaks production (aprile 2026). Il post nomina il pattern di fallimento direttamente: "ha passato la code review, è stato deployato senza eval gate, ha colpito la produzione senza A/B per utente e non ha innescato alcun rollback automatico." Un post compagno — LLM postmortem template — fields SRE missed — enumera i campi fetta / journey / per-utente che i postmortem attuali sistematicamente omettono.
Una nota su cosa non è in questo grafico. Il tempo di kubectl rollout undo di Kubernetes è governato dalle tue impostazioni maxSurge / maxUnavailable e dal warm-up dei pod, non dal comando stesso, e non siamo riusciti a trovare una fonte primaria che pubblichi un numero misurato nel modo in cui lo fanno le quattro fonti qui sopra — quindi l’abbiamo lasciato fuori invece di riempirlo con una stima.
Prossimo in questa serie: 10 fallimenti di rilascio CI/CD che abbiamo catturato in LM personalizzati, e quale stadio della pipeline cattura ciascuno. Tre dei dieci sono regressioni per fetta che un gate aggregato avrebbe spedito. Altri due sono cali silenziosi di qualità che un canary su metrica infrastrutturale avrebbe promosso. Il resto è il tipo di modalità di fallimento che ogni pipeline di rilascio dovrebbe catturare — li elenchiamo perché vale la pena dire ad alta voce quali, di fatto, una pipeline con gate aggregato cattura da sola.
Ready to Build Your Custom AI Solution?
Discover how Divinci AI can help you implement RAG systems, automate quality assurance, and streamline your AI development process.
Get Started Today