
Notes from the Release Cycle — भाग I
जब हमने पहली बार एक सामान्य CI/CD पाइपलाइन के माध्यम से एक LLM शिप करने की कोशिश की, तो बिल्ड हरा हो गया, डिप्लॉय सफल रहा, और सात मिनट के भीतर कस्टमर सपोर्ट टिकट दर्ज होने लगे।
कुछ भी “टूटा” नहीं था। सभी 4,200 इंटीग्रेशन टेस्ट पास हुए। लेटेंसी अपरिवर्तित थी। 200 OK रेट स्थिर बनी रही। लेकिन क़ानूनी डोमेन के प्रश्नों के एक विशिष्ट वर्ग पर, नया मॉडल चुपचाप हेजिंग शुरू कर चुका था — उस उत्तर के लिए प्रतिबद्ध होने से इनकार कर रहा था जिसे पिछले संस्करण ने सही ढंग से उत्तरित किया था। कोई भी टेस्ट इसे पकड़ नहीं पाया क्योंकि हमने अभी तक एक भी लिखा नहीं था।
हमने रोलबैक किया, और रोलबैक स्वयं एक घटना थी। मॉडल आर्टिफ़ैक्ट तीन जगहों पर रहता था, प्रॉम्प्ट टेम्पलेट चौथी जगह पर, राउटिंग नियम पाँचवीं जगह पर, और किसी को किसी और के बारे में कुछ भी पता नहीं था। पिछली अच्छी स्थिति में वापस आने में दो घंटे से थोड़ा अधिक समय लगा। उस विंडो के दौरान जिन ग्राहकों को हेज मिला, वे प्रभावित नहीं थे।
वही आउटेज इस पाइपलाइन के अस्तित्व का कारण है। आगे जो है वह वास्तविक पाइपलाइन है जिसके माध्यम से हम अपनी रिलीज़ शिप करते हैं, और वही जिसे हम Divinci API के माध्यम से उन ग्राहकों के लिए उजागर करते हैं जो अपनी रिलीज़ शिप कर रहे हैं। इसमें चार चरण हैं — register, gate, roll, observe — और हर चरण में एक रोलबैक पथ है जो किसी मनुष्य के जागते रहने पर निर्भर नहीं करता।
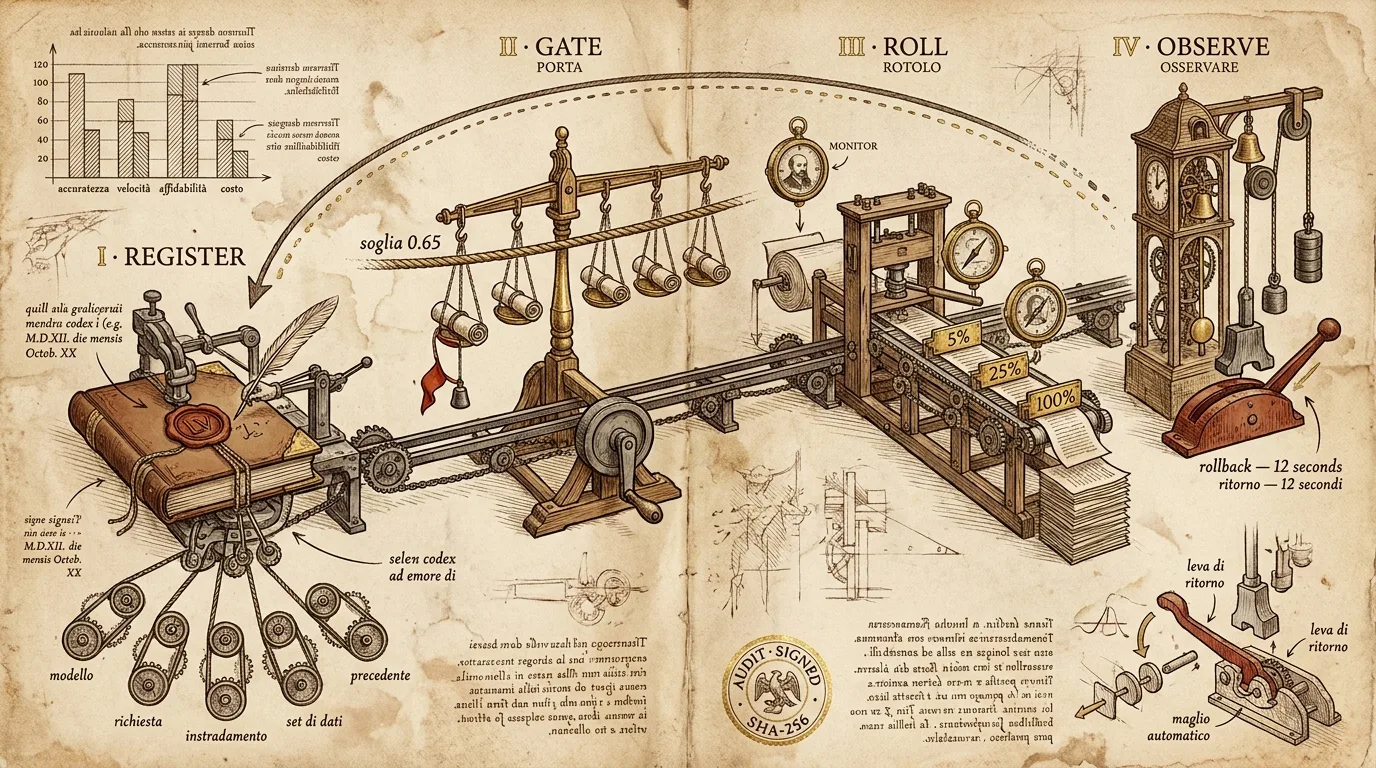
चार चरण

ये चरण जानबूझकर कठोर हैं। हर रिलीज़ इसी क्रम में हर चरण से गुज़रती है। एक “हॉटफ़िक्स” पथ जो मूल्यांकन छोड़ देता है — मौजूद नहीं है। हमने एक बार ऐसा कोशिश किया था।
चरण 1 — Register
एक रिलीज़ केवल एक मॉडल वेट फ़ाइल नहीं है। एक रिलीज़ एक अपरिवर्तनीय मेनिफ़ेस्ट है जो इन सबको बंडल करता है:
- मॉडल आर्टिफ़ैक्ट (HF रिपो + कमिट SHA, या एक vIndex पैच)
- प्रॉम्प्ट टेम्पलेट (हर वेरिएबल, हर सिस्टम मैसेज)
- राउटिंग नियम (कौन सा ट्रैफ़िक क्लास किस संस्करण पर जाता है)
- गेट थ्रेशोल्ड्स की गणना के लिए उपयोग किया गया डेटासेट संस्करण
- पिछली रिलीज़ का SHA, ताकि रोलबैक स्पष्ट हो
curl -X POST https://api.divinci.ai/v1/releases \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{
"model_ref": "Divinci-AI/gemma-4-e2b@a7c91f",
"prompt_template_ref": "templates/legal-qa@v14",
"routing": { "domain": "legal" },
"dataset_version": "scored-qa-medical-v3",
"previous_release": "rel_8f72b1"
}'
# → { "release_id": "rel_a01c66", "manifest_sha256": "9abaeaf6..." }मेनिफ़ेस्ट SHA पाइपलाइन में किसी के द्वारा भी उपयोग किया जाने वाला एकमात्र हैंडल है। यदि दो लोग वही रिलीज़ डिप्लॉय करते हैं जिसे वे एक ही मानते हैं और SHA अलग हैं, तो पाइपलाइन डिप्लॉय को अस्वीकार कर देती है। इस नियम से हम अब तक दो बग पकड़ चुके हैं।
चरण 2 — Gate
गेट वह हिस्सा है जिसे अधिकांश CI पाइपलाइनें ग़लत समझती हैं। Lighthouse-शैली के heuristics — perplexity, BLEU, ROUGE — एक रिग्रेशन को पास होने देंगे यदि वह रिग्रेशन एक डोमेन में केंद्रित है। एग्रीगेट स्कोर उसे धो डालते हैं।
Divinci का गेट उस scored-QA सूट को चलाता है जिसके साथ रिलीज़ मेनिफ़ेस्ट रजिस्टर किया गया था, और एक प्रति-श्रेणी Spearman थ्रेशोल्ड लागू करता है:

ऊपर के चार्ट में दिखाई गई रिलीज़ एक एग्रीगेट गेट से पास हो जाएगी (मीन 0.64 “काफ़ी क़रीब” है)। यह Divinci के गेट से फ़ेल हो जाती है क्योंकि IP licensing पहले के 0.68 से 0.41 पर क्रैश हो जाता है — ठीक उसी प्रकार का स्थानीयकृत रिग्रेशन जिसे कोई नोटबुक कभी नहीं पकड़ता।
हमने स्लाइस-अवेयर गेटिंग केवल मज़े के लिए नहीं बनाई। यह LLM पोस्टमॉर्टम की वर्तमान फ़सल में सीधे नामित failure mode है। Tianpan का “The Semver Lie” लेख[6] एक प्रॉम्प्ट परिवर्तन का वर्णन करता है जो “कोड रिव्यू पास हुआ, eval गेट्स के बिना डिप्लॉय हुआ, बिना प्रति-उपयोगकर्ता A/B के प्रोडक्शन में पहुँचा, और किसी भी ऑटोमैटिक रोलबैक को ट्रिगर नहीं किया।” जिसने उस घटना को मात्र कष्टप्रद के बजाय विनाशकारी बनाया वह यह था कि रिग्रेशन एक स्लाइस में केंद्रित था — एक एकल user-journey क्लास — जबकि एग्रीगेट बना रहा। 2026 में हमने जिन LLM रिलीज़ टूल्स का सर्वे किया उनमें से हर एक या तो एक सिंगल ग्लोबल स्कोर पर गेट करता है, या बिल्कुल गेट नहीं करता। उनमें से कोई भी गेट को स्लाइस नहीं करता।
गेट फ़ेलियर एक सॉफ्ट चेतावनी नहीं है। release_id को gate_fail के रूप में चिह्नित किया जाता है, मेनिफ़ेस्ट आर्काइव कर दिया जाता है, और कोई भी डिप्लॉय कमांड उसे स्वीकार नहीं करेगी। Cold-start रिलीज़ — एक बिल्कुल नया मॉडल जिसके पास तुलना करने के लिए ऐतिहासिक Spearman नहीं है — एक एकमुश्त --force-gate-override पथ से गुज़रती हैं जिसके लिए एक लिखित औचित्य की आवश्यकता होती है; औचित्य, उपयोगकर्ता ID, और एक gate_override_sha256 सीधे ऑडिट ट्रेल में जाते हैं। ओवरराइड इसलिए मौजूद है क्योंकि इसके लिए वैध स्थितियाँ हैं; ऑडिट ट्रेल इसलिए मौजूद है क्योंकि भविष्य के आपको औचित्य पढ़ने की आवश्यकता पड़ेगी।
चरण 3 — Roll
Divinci में एक कैनरी का अर्थ है तीन चेकपॉइंट: 5%, 25%, 100%। हर चेकपॉइंट पर, पाइपलाइन कॉन्फ़िगर किए गए dwell time या कॉन्फ़िगर की गई request count में से जो बाद में हो उसके लिए होल्ड करती है। डिफ़ॉल्ट 5% पर 4 मिनट / 1,000 अनुरोध है, 25% पर 15 मिनट / 10,000 अनुरोध।
हर चेकपॉइंट पर, तीन मॉनिटर बने रहने चाहिए:
- p95 लेटेंसी पिछली रिलीज़ की p95 के 1.2× के भीतर
- 5xx रेट पिछली रिलीज़ की दर के 1.5× के भीतर
- आउटपुट-गुणवत्ता मॉनिटर: कैंडिडेट रिलीज़ के माध्यम से हाल के प्रोडक्शन ट्रेस का निरंतर रीप्ले, उसी कैलिब्रेटेड जज द्वारा स्कोर किया गया जिसने चरण 2 को पावर दिया था
तीसरा वह है जो किसी अन्य रिलीज़ पाइपलाइन में शामिल नहीं है। SageMaker, KServe, BentoML, Vertex AI — ये सभी लेटेंसी और एरर रेट पर नज़र रखते हैं। उनमें से कोई भी कैंडिडेट के आउटपुट का स्कोर उन वास्तविक प्रश्नों के विरुद्ध नहीं करता जो प्रोडक्शन अभी पूछ रहा है। कैंडिडेट को वही प्रॉम्प्ट मिलते हैं जो सक्रिय रिलीज़ को अभी मिले, उन्हें 5% मिरर पर चलाता है, और हम कैलिब्रेटेड ग्रेडर के विरुद्ध कैंडिडेट के उत्तरों का Spearman ρ मापते हैं। 5xx रेट साफ़ रह सकता है जबकि मॉडल चुपचाप हेज करता है, इनकार करता है, या मतिभ्रम करता है। हमने यह होते देखा है। trace-replay मॉनिटर वह है जो इसे पकड़ता है।
रीप्ले सेट सीमित है — हम लागत को पूर्वानुमेय रखने के लिए प्रति स्लाइस प्रति चेकपॉइंट 50 हालिया ट्रेस पर कैप लगाते हैं। 5% ट्रैफ़िक पर ग्रेडिंग में लगभग 90 सेकंड लगते हैं। एक फ्लैट प्रतिशत-कैनरी से धीमा, किसी ग्राहक के टिकट दर्ज करने का इंतज़ार करने से तेज़।
# roll कमांड fire-and-forget है। पाइपलाइन ख़ुद को होल्ड करती है।
curl -X POST https://api.divinci.ai/v1/releases/rel_a01c66/roll \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{ "strategy": "canary", "dwell_5pct_seconds": 240, "dwell_25pct_seconds": 900 }'
# → { "rollout_id": "rol_b3e2", "next_checkpoint_at": "2026-05-26T09:04:00Z" }चरण 4 — Observe, रोलबैक, और रसीद
यह वह चरण है जो पाइपलाइन के अस्तित्व को सार्थक बनाता है।
रोलआउट पूरा होने के बाद observer निरंतर चलता है। यह एक रोलिंग 5% trace-replay sample पर प्रति-मिनट आउटपुट-गुणवत्ता स्कोर की गणना करता है। यदि स्कोर रोलबैक थ्रेशोल्ड (डिफ़ॉल्ट: गेट थ्रेशोल्ड का 0.85, यानी 0.55 यदि गेट 0.65 था) से तीन लगातार मिनटों तक नीचे गिरता है, तो रोलबैक स्वचालित रूप से फ़ायर हो जाता है। कोई page नहीं, कोई मनुष्य नहीं, कोई बहस नहीं।
रोलबैक स्वयं एक एकल निर्देश है: मेनिफ़ेस्ट से previous_release पर राउटिंग को फिर से इंगित करें। चूँकि पिछली रिलीज़ एक पूरी तरह से बंडल किया गया मेनिफ़ेस्ट थी, हर घटक — weights, prompt, routing, dataset — एटॉमिक रूप से फ़्लिप होता है।
फिर रसीद फ़ायर होती है।
हर रिलीज़ निर्णय — register, gate-pass, gate-fail, gate-override, checkpoint-promote, checkpoint-hold, auto-rollback, manual-rollback — एक रिलीज़ रसीद उत्सर्जित करता है: एक JSON-with-SHA-256 आर्टिफ़ैक्ट, इस ग्राहक के लिए पिछली रसीद और इस रिलीज़ के लिए पिछली रसीद से hash-chained, बाहरी रूप से एक ऐसी अनुसूची पर एंकर्ड जिसे ग्राहक कॉन्फ़िगर करता है।
जब रिलीज़ एक ओपन-वेट्स मॉडल द्वारा समर्थित होती है — Gemma, Qwen, Llama, Mistral, GPT-OSS, कोई भी जहाँ वज़न ऐड्रेसेबल और एडिटेबल हों — तो रसीद एक vIndex attestation एम्बेड करती है: एक क्रिप्टोग्राफ़िक प्रमाण कि निर्णय के समय सक्रिय वज़न वही वज़न हैं जो मेनिफ़ेस्ट ने रजिस्टर किए थे। यही वह पथ है जो कठिन अनुपालन माँगों को पूरा करता है (GDPR Article 17 right-to-erasure, EU AI Act provenance) क्योंकि आप केवल यह नहीं सिद्ध कर सकते कि क्या डिप्लॉय किया गया था बल्कि यह भी कि अंतर्निहित वज़न वही हैं जो वे दावा करते हैं।
जब रिलीज़ एक क्लोज़्ड-वेट्स मॉडल द्वारा समर्थित होती है — OpenAI, Anthropic, Google, कोई भी जो केवल एक अपारदर्शी API के माध्यम से सेवित होता है — तो रसीद फिर भी निर्णय श्रृंखला को कवर करती है (कौन सा मेनिफ़ेस्ट, कौन सा गेट परिणाम, कौन सा मॉनिटर रीडिंग, कौन सा उपयोगकर्ता ने कौन सी क्रिया ट्रिगर की) लेकिन अंतर्निहित वज़न को attest नहीं कर सकती, क्योंकि हम उन्हें देख नहीं सकते। यह पाइपलाइन की सीमा नहीं है; यह उस सीमा है कि क्या सत्यापन योग्य है जब प्रदाता वज़न उजागर नहीं करता। जिन ऑडिटर्स को इस भेद की परवाह है उन्हें रसीद में ही सच्चा उत्तर मिलता है।
किसी भी तरह से, आज ऑडिटर्स को logs मिलते हैं। इस पाइपलाइन के साथ, उन्हें उन सब चीज़ों के प्रमाण मिलते हैं जो वास्तव में प्रमाणित की जा सकती हैं। हमने बाज़ार में किसी और को यह शिप करते नहीं देखा। हम उम्मीद करते हैं कि वे करेंगे — EU AI Act की समय-सीमाएँ अंततः इसे अनिवार्य बनाती हैं। हमने इसे अभी शिप करने का चुनाव किया।
ये हमारी संख्याएँ नहीं हैं — ये वास्तविक पोस्टमॉर्टम, प्लेटफ़ॉर्म दस्तावेज़ीकरण, और DORA फ़्रेमवर्क से प्रकाशित प्राथमिक-स्रोत संख्याएँ हैं। यह विरोधाभास ही है जो Divinci के डिज़ाइन को प्रेरित करता है। Atlassian के अप्रैल 2022 आउटेज[1] में प्रति साइट बारह घंटे लगे क्योंकि स्टेट कई सिस्टम्स में फैला था जिन्हें फिर से सहमति में समन्वित करना था। Cloudflare के जून 2022 आउटेज[2] में revert करने में चौवालीस मिनट लगे क्योंकि, उनके अपने शब्दों में, इंजीनियर एक-दूसरे के revert पर पैर रख रहे थे। AWS SageMaker के कैनरी deployment guardrails[4] रोलबैक के पूरी तरह पूर्ण होने से पहले डिफ़ॉल्ट दस-मिनट के termination wait का दस्तावेज़ीकरण करते हैं। DORA[3] failed-deployment recovery के लिए elite थ्रेशोल्ड “एक घंटे से कम” है — यह वह बार है जिसे एक उच्च-प्रदर्शन वाले संगठन से पार करने की उम्मीद की जाती है, छत नहीं।
बारह सेकंड भी कोई जादुई संख्या नहीं है। यह वह समय है जो routing layer को in-flight अनुरोधों को drain करने, सक्रिय मेनिफ़ेस्ट को स्वैप करने, और पूरे क्षेत्रों में नई स्थिति को ack करने के लिए चाहिए। धीमा हिस्सा in-flight drain है। कोई तेज़ रास्ता नहीं है जो generation के बीच में responses न गिराए।
यह क्या है, जो अन्य LLM रिलीज़ टूल्स नहीं हैं
इसे बनाने से पहले हमने 2026 में बारह अन्य टूल्स का सर्वे किया — LangSmith Deployment, W&B Models, MLflow, SageMaker Deployment Guardrails, Vertex AI Endpoints, Seldon Core, BentoCloud, KServe, Humanloop, Braintrust, Patronus AI, Arize Phoenix। वे दो शिविरों में बँटते हैं जो ठीक से मिलते नहीं।
eval-CI शिविर — Braintrust, Humanloop, Patronus — ऑफ़लाइन eval स्कोर पर PR मर्ज को गेट करता है। वे कभी भी running service को नहीं छूते। जब मॉडल प्रोडक्शन में होता है और गुणवत्ता गिरती है, तो वे अलर्ट करते हैं; किसी और को रोलबैक करना होता है।
serving-canary शिविर — SageMaker Deployment Guardrails, KServe, Vertex AI, BentoCloud, Seldon Core — ट्रैफ़िक को विभाजित करता है और ऑटो-रोलबैक करता है। लेकिन उनमें से हर एक इन्फ़्रास्ट्रक्चर मेट्रिक्स पर ट्रिगर होता है: p99 लेटेंसी, एरर रेट, CloudWatch अलार्म। उनमें से कोई भी quality regression पर ऑटो-रोलबैक नहीं करता। वे कर नहीं सकते, क्योंकि उनके पास प्रोडक्शन आउटपुट पर चल रहा कोई judge नहीं है।
“PR मर्ज पर eval पास हुआ” और “जिन user journeys की हम वास्तव में परवाह करते हैं उन पर लाइव कैनरी scored हुआ” के बीच का जोड़ हर टीम को वर्तमान में स्वयं ब्रिज करना पड़ता है। ब्लॉग पोस्ट इसे 2026 के प्रमुख failure mode के रूप में पहचानती है[6]। हमने इसे बंद कर दिया। विशेष रूप से:
- गेट sliced है। एक मानव-एंकर्ड ग्रेडर के विरुद्ध प्रति-डोमेन Spearman ρ, एक एकल ग्लोबल स्कोर नहीं। हर अन्य गेट के पास slice-blindness है।
- कैनरी आउटपुट गुणवत्ता देखता है, केवल p95 नहीं। कैंडिडेट के माध्यम से निरंतर trace-replay, उसी judge द्वारा स्कोर किया गया जिसने गेट को पावर दिया था। यही गुम जोड़ है।
- हर निर्णय एक रिलीज़ रसीद उत्सर्जित करता है। Hash-chained, बाहरी रूप से anchorable, JSON-with-SHA-256 फ़ॉर्मेट में जो हमारे अनुपालन पृष्ठों को समर्थन देता है। ओपन-वेट्स मॉडल बैकिंग के लिए — Gemma, Qwen, Llama, Mistral, GPT-OSS — रसीद एक vIndex weight-attestation एम्बेड करती है ताकि ऑडिटर्स यह सिद्ध कर सकें कि लाइव वज़न वास्तव में क्या थे। क्लोज़्ड-API बैकिंग के लिए, रसीद निर्णय श्रृंखला को कवर करती है लेकिन वज़न provenance का दावा नहीं करती, क्योंकि प्रदाता वज़न उजागर नहीं करता। किसी भी तरह से, ऑडिटर्स को उन चीज़ों के प्रमाण मिलते हैं जो वास्तव में सिद्ध की जा सकती हैं, केवल logs नहीं।
बस इतना ही। Generic कैनरी, version registry, infra-metric रोलबैक — ये commodity हैं। हमने एक generic कैनरी नहीं लिखी।
यह क्या नहीं हल करता
तीन ईमानदार सीमाएँ:
गेट केवल उतना ही अच्छा है जितना डेटासेट। एक scored-QA सूट जो उस डोमेन को कवर नहीं करती जिसे ग्राहक वास्तव में उपयोग करता है, उस डोमेन में regressions नहीं पकड़ेगी। हमने यह दो बार देखा है। दोनों बार ग्राहक का पहला कदम एक नई scored-QA सूट शिप करना था, मॉडल बदलना नहीं। यही सही कदम है।
रोलबैक यह मान कर चलता है कि पिछली रिलीज़ अच्छी थी। यदि एक regression तीन रिलीज़ तक लाइव रहा है और किसी ने नहीं देखा, तो एक रिलीज़ रोलबैक करना आपको थोड़ा कम-ख़राब मॉडल देता है। ऑडिट ट्रेल यहाँ मदद करता है — आप SHA द्वारा किसी भी पिछले मेनिफ़ेस्ट पर रोलबैक कर सकते हैं, केवल N-1 नहीं।
Cold-start रिलीज़ कैनरी को बायपास करती हैं। एक बिल्कुल नया मॉडल जिसके पास तुलना करने के लिए प्रोडक्शन ट्रैफ़िक नहीं है, उसे सार्थक रूप से कैनरी नहीं किया जा सकता। हम इसके बजाय 24-घंटे की shadow डिप्लॉयमेंट को मजबूर करते हैं, जो आउटपुट का अवलोकन करती है पर उन्हें serve नहीं करती। यह धीमी और कम सुविधाजनक है। यह एकमात्र ईमानदार उत्तर भी है।
इसका सबसे छोटा संस्करण जो आप चला सकते हैं
यदि आप Divinci का उपयोग किए बिना ऐसा कुछ खड़ा करना चाहते हैं, तो न्यूनतम व्यवहार्य संस्करण लगभग है:
- एक registry जो मॉडल + प्रॉम्प्ट + राउटिंग + डेटासेट को एक एकल अपरिवर्तनीय आर्टिफ़ैक्ट के रूप में संग्रहीत करती है, content hash द्वारा सम्बोधित
- एक judge जो Spearman ρ के माध्यम से एक मानव-एंकर्ड पैनल के विरुद्ध कैलिब्रेट किया गया है — और एक गेट निर्णय जो प्रति-स्लाइस स्कोर से परामर्श करता है, केवल एग्रीगेट नहीं
- एक traffic splitter जो checkpoints पर होल्ड करता है और एक freshness-bounded गुणवत्ता मॉनिटर से परामर्श करता है — जहाँ मॉनिटर हाल के प्रोडक्शन ट्रेस को कैंडिडेट के माध्यम से रीप्ले करता है, केवल synthetic ट्रेस का sample नहीं लेता
- एक routing layer जिसकी state एटॉमिक रूप से swap की जा सके — जिसमें प्रॉम्प्ट टेम्पलेट शामिल है, केवल वज़न नहीं
- एक audit log जो हर रिलीज़ निर्णय के लिए एक hash-chained, बाहरी रूप से-anchorable रसीद उत्सर्जित करता है — साथ ही एक weight-attestation embed जब मॉडल ओपन-वेट्स है, क्योंकि closed-API रिलीज़ का भौतिक रूप से वज़न स्तर पर attest नहीं किया जा सकता
अधिकांश टीमों के पास पहले से (1) और (3) है। कठिन हिस्से (2), (4), और (5) हैं। Divinci के अस्तित्व का कारण यह है कि हमने पहले स्वयं के लिए सभी पाँच बनाए, फिर महसूस किया कि बाक़ी सबको भी इनकी ज़रूरत पड़ने वाली थी।
यदि आप build छोड़ना चाहते हैं, तो API संदर्भ यहाँ है, और “Release Management” अनुभाग में रिलीज़ endpoints इस पाइपलाइन का पूरा सतह है। अनुपालन पक्ष — वे vIndex रसीदें कैसी दिखती हैं और वे EU AI Act, GDPR Article 17, HIPAA, और NIST AI RMF पर कैसे मैप होती हैं — अनुपालन पृष्ठ पर है। इस पोस्ट में हर command एक वास्तविक endpoint है।
References
- Atlassian — Post-Incident Review: April 2022 Outage. लेख से: "The accelerated Restoration 2 approach took approximately 12 hours to restore a site." 883 ग्राहक साइट्स का पूर्ण पुनर्स्थापन 14 दिन लगा। इन्फ़्रास्ट्रक्चर, बैकअप्स, और प्रति-साइट validation में फैली state प्रति-साइट संख्या को मिनट्स के बजाय घंटों में ले जाती है।
- Cloudflare — Cloudflare outage on June 21, 2022. पोस्ट में शब्दशः उद्धृत timeline: "06:58: Root cause found and understood. Work begins to revert the problematic change… 07:42: The last of the reverts has been completed." "हमें पता है क्या revert करना है" से "revert पूरा हो गया" तक चौवालीस मिनट, कुछ हद तक इसलिए क्योंकि इंजीनियर एक-दूसरे के reverts पर पैर रख रहे थे।
- DORA — Software delivery performance metrics. "failed deployment recovery time" elite-performer थ्रेशोल्ड एक घंटे से कम के रूप में दस्तावेज़ीकृत है। DORA की ऐतिहासिक रिपोर्ट्स में low performers हफ़्तों-से-महीनों में मापे जाते हैं।
- AWS SageMaker — Use canary traffic shifting और सहयोगी Auto-Rollback Configuration and Monitoring पृष्ठ। उदाहरण
TerminationWaitInSeconds600 (दस मिनट) है;MaximumExecutionTimeoutInSeconds1800 (तीस मिनट) पर bounded है। एक बार अलार्म ट्रिप होने पर baking window के भीतर रोलबैक फ़ायर होता है: "If any of the alarms trip during the baking period, then SageMaker AI initiates a rollback and all traffic returns to the blue fleet." - Divinci AI — रिलीज़ मेनिफ़ेस्ट के माध्यम से एटॉमिक routing-flip। बारह सेकंड एक ~100-replica सेवा पर in-flight drain time है; मेनिफ़ेस्ट swap स्वयं sub-second है। यह संख्या हमारी अपनी सेवा से है, किसी benchmark से नहीं; जो आर्किटेक्चर इसे संभव बनाता है वह ऊपर वर्णित bundled मेनिफ़ेस्ट है (चरण 1 — Register)।
- Tianpan — The Semver Lie: how an LLM minor update breaks production (April 2026). लेख failure pattern को सीधे नामित करता है: "passed code review, deployed without eval gates, hit production without per-user A/B, and triggered no automatic rollback." एक सहयोगी पोस्ट — LLM postmortem template — fields SRE missed — slice / journey / प्रति-उपयोगकर्ता fields की गणना करती है जिन्हें वर्तमान postmortems व्यवस्थित रूप से छोड़ देती हैं।
एक बात के बारे में जो इस चार्ट पर नहीं है। Kubernetes kubectl rollout undo समय आपकी maxSurge / maxUnavailable सेटिंग्स और pod warm-up द्वारा नियंत्रित होता है, command स्वयं द्वारा नहीं, और हम एक प्राथमिक स्रोत नहीं ढूँढ पाए जो उस तरह से एक मापी गई संख्या प्रकाशित करता हो जैसा ऊपर के चार स्रोत करते हैं — इसलिए हमने उसे एक अनुमान से भरने के बजाय छोड़ दिया।
इस श्रृंखला में अगला: कस्टम LMs में 10 CI/CD रिलीज़ failures जिन्हें हमने पकड़ा, और पाइपलाइन का कौन सा चरण हर एक को पकड़ता है। दस में से तीन slice-aware regressions हैं जिन्हें एक एग्रीगेट गेट शिप कर देता। दो और silent quality drops हैं जिन्हें एक infra-metric कैनरी प्रोमोट कर देता। बाक़ी वही failure mode हैं जिन्हें हर रिलीज़ पाइपलाइन को पकड़ना चाहिए — हम उन्हें इसलिए सूचीबद्ध करते हैं क्योंकि यह ज़ोर से कहना सार्थक है कि एक एग्रीगेट-गेटेड पाइपलाइन वास्तव में किन्हें स्वयं पकड़ती है।
Ready to Build Your Custom AI Solution?
Discover how Divinci AI can help you implement RAG systems, automate quality assurance, and streamline your AI development process.
Get Started Today