
Notes du cycle de publication — Partie IV
Une directrice juridique entre dans la revue d’ingénierie. Elle pose une seule question : « Si la demande de droit à l’effacement de l’article 17 de l’EU AI Act arrive demain pour supprimer chaque fait que notre modèle a appris sur un patient spécifique, pouvons-nous prouver que nous l’avons fait ? »
La réponse honnête que la plupart des équipes doivent donner est : « Nous pouvons affiner le modèle pour qu’il oublie. Nous pouvons vous montrer la session d’entraînement. Mais nous ne pouvons pas prouver que l’information a structurellement disparu, car elle pourrait refaire surface sous le bon prompt adverse. »
Ce n’est pas une réponse de conformité. C’est une non-réponse avec un haussement d’épaules procédural.
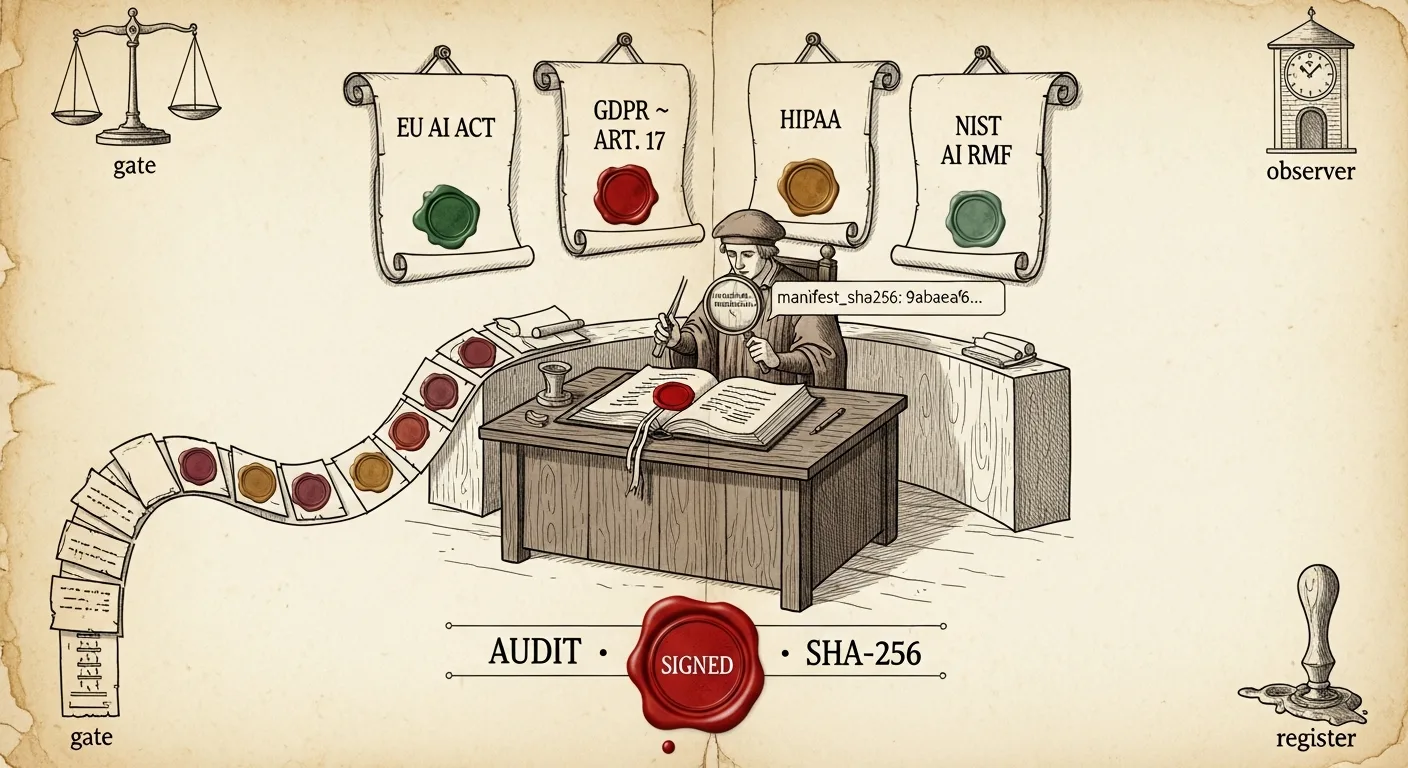
Ce billet traite de ce à quoi ressemble une véritable réponse de conformité pour des LLM personnalisés — à travers quatre cadres réglementaires (EU AI Act, article 17 du RGPD, HIPAA, NIST AI RMF), mis en correspondance avec le pipeline en quatre étapes (Enregistrer → Filtrer → Déployer → Observer) que nous livrons pour les publications clients. La tension de fond qui traverse chaque demande des régulateurs est poids ouverts vs API fermée : les choses que vous pouvez prouver sur un fine-tune Gemma 4 ne sont pas les choses que vous pouvez prouver sur une publication servie derrière une API opaque d’un fournisseur. Le format de reçu que nous utilisons le dit explicitement, ligne par ligne. C’est cette honnêteté qui rend le reçu utile à un auditeur.
Les quatre régulateurs et ce que chacun veut réellement
Les discussions de conformité ont tendance à se réduire à « nous avons documenté les choses ». Cette formulation échoue face à un auditeur. Ce que les auditeurs veulent, ce sont des preuves qu’ils peuvent vérifier sans avoir à faire confiance à votre infrastructure. Les quatre cadres ci-dessous utilisent tous des vocabulaires différents pour la même demande sous-jacente.
Les montants des sanctions ne sont pas ce qui rend ces cadres intéressants. Les montants des sanctions sont ce qui les rend structurants. La partie intéressante, c’est la primitive de vérification — ce à quoi chaque cadre veut réellement que l’artefact ressemble. Trois des quatre demandent une preuve de niveau cryptographique dans des vocabulaires différents. Le quatrième (NIST AI RMF) est volontaire, mais devenu de facto obligatoire dans les processus d’achat en entreprise. Ils convergent vers la même forme : un artefact qu’un auditeur peut vérifier sans faire confiance à vos journaux.
La fracture : poids ouverts vs API fermée
Avant la mise en correspondance étape par étape, l’avertissement le plus important de tout ce billet :
Pour les bases de modèle à poids ouverts — Gemma, Qwen, Llama, Mistral, GPT-OSS, tout ce dont les poids sont adressables et modifiables — chaque décision de publication Divinci émet un reçu vIndex qui inclut une attestation de poids : une preuve cryptographique que les poids actifs au moment de la décision sont exactement les poids enregistrés par le manifeste. C’est ce qui rend possible l’effacement vérifiable au titre de l’article 17 du RGPD. Vous appliquez un patch DELETE qui supprime une relation entité-relation spécifique de l’espace des poids, le reçu intègre le hash avant/après, et un auditeur peut vérifier que la suppression a eu lieu en réexécutant la vérification contre le vIndex public.
Pour les bases de modèle à API fermée — OpenAI, Anthropic, Google via des API opaques — le même reçu couvre la chaîne de décision (quel manifeste, quel résultat de filtre, quelle lecture du moniteur, quel utilisateur a déclenché quelle action) mais ne peut pas revendiquer la provenance des poids, car le fournisseur n’expose pas les poids. Le reçu le note explicitement dans un champ weight_attestation: null avec une note expliquant pourquoi. Ce n’est pas une posture de conformité dégradée — c’est la limite de ce qui est vérifiable, consignée honnêtement. Un auditeur qui lit le reçu comprend exactement quelle classe de preuve est et n’est pas apportée.
Cette fracture traverse chaque demande des régulateurs ci-dessous. Chaque fois qu’un cadre exige quelque chose au niveau des poids, le chemin poids ouverts peut le satisfaire et le chemin API fermée ne le peut pas. Nous le disons dans le reçu plutôt que de laisser entendre une preuve que nous ne pouvons pas livrer.
Comment chaque cadre se projette sur les quatre étapes du pipeline
Le pipeline comporte quatre étapes. La demande de chaque régulateur correspond à une ou plusieurs d’entre elles. La matrice ci-dessous est la carte réelle.
Les deux cellules ◐ sont les entrées « article 17 du RGPD / poids ouverts uniquement » — ce sont les demandes que le chemin API fermée ne peut pas pleinement satisfaire. Tout le reste s’applique aux deux types de base.
La suite du billet parcourt la contribution de chaque étape.
Étape ① — Enregistrer
L’étape Enregistrer produit un manifeste JSON immuable, adressé par SHA-256. Pour les publications réglementées, le manifeste porte tout ce que demande l’Annexe IV[1] en un seul artefact :
- L’artefact du modèle (dépôt HF + SHA du commit, ou référence à un patch vIndex)
- Le template de prompt (chaque variable, chaque message système — versionné)
- Les règles de routage (quelle classe de trafic atterrit sur quelle publication)
- La version du jeu de données utilisée pour calculer les seuils du filtre (synthèse des données d’entraînement par hash)
- Le SHA de la publication précédente (pour que la chaîne d’audit soit ininterrompue)
- Le périmètre de divulgation — pour les déploiements HIPAA, quelles catégories de PHI le modèle est autorisé à recevoir
Le manifeste est la documentation. Un auditeur ne lit pas un texte ; il lit le hash du manifeste et vérifie le bundle. Aucune synthèse rédigée six mois plus tard n’est nécessaire.
Bonus poids ouverts. Lorsque l’artefact du modèle référence un modèle à poids ouverts, le manifeste intègre également le vindex_sha256 — l’empreinte cryptographique du vIndex publié du modèle. Cette empreinte est ce qui permet à un tiers de vérifier les poids actifs sans jamais avoir à faire confiance à notre infrastructure de déploiement.
Réserve API fermée. Lorsque l’artefact du modèle référence un modèle en API fermée, le champ vindex_sha256 du manifeste est null, et la weight_attestation_class du manifeste est decision_chain_only. L’auditeur qui le lit sait exactement ce qui est revendiqué et ce qui ne l’est pas.
Étape ② — Filtrer
L’étape Filtrer est l’endroit où les « mesures de supervision humaine »[1] de l’EU AI Act sont opérationnalisées. Un régulateur qui lit l’EU AI Act et en conclut « il nous faut un workflow d’approbation humaine » est passé à côté de l’essentiel — la demande la plus difficile est contre quoi l’humain approuve. L’étape Filtrer répond à cette question avec un ρ de Spearman par tranche, ancré sur un évaluateur humain[3]. Chaque tranche qui compte dans votre posture réglementaire (oncologie pédiatrique, licences PI, français de Belgique) a son propre seuil. Le chemin de dérogation exige une justification écrite qui entre dans la piste d’audit.
Pour les déploiements couverts par HIPAA, c’est aussi là que vit la règle de divulgation « minimum nécessaire ». La suite de QA notée du filtre comprend des tests négatifs pour la sur-exposition de PHI — des réponses qui incluent des identifiants personnels alors qu’aucun n’a été demandé. Une publication qui régresse sur la tranche de sur-exposition échoue au filtre, quelles que soient ses performances sur les autres tranches.
Pour NIST AI RMF, l’étape Filtrer couvre la fonction « mesurer » — les preuves numériques par tranche que le système fonctionne dans les tolérances configurées.
Étape ③ — Déployer
La surveillance post-commercialisation de l’EU AI Act[1] exige de l’opérateur qu’il démontre une observation continue — pas seulement avant le lancement — du comportement du système d’IA dans des conditions réelles. Un canary 5 % → 25 % → 100 % avec des points de contrôle de surveillance qualité est la façon la plus naturelle de la satisfaire. Le temps d’attente à chaque point de contrôle, plus les lectures du moniteur pendant cette attente, est ce qu’un auditeur veut voir.
Pour HIPAA, l’étape canary est aussi l’endroit où la journalisation d’audit par requête est exercée de bout en bout. Chaque point de contrôle produit un échantillon de reçus requête-réponse signés ; si certains présentent une gestion mal configurée des PHI, cela apparaît à 5 % du trafic plutôt qu’à 100 %.
Étape ④ — Observer
C’est l’étape qui mérite l’histoire de conformité. L’étape Observer exécute en continu la rejouabilité des traces à travers la publication active, notée par le même juge humain-ancré que le filtre, avec un moniteur qualité qui déclenche un rollback automatique en cas de dépassement.
Chaque décision de publication — enregistrement, succès de filtre, échec de filtre, dérogation au filtre, promotion de point de contrôle, mise en attente d’un point de contrôle, rollback automatique, rollback manuel, et toute application d’un patch DELETE article 17 du RGPD — émet un reçu vIndex. Chaîné par hachage au reçu précédent pour ce client et au reçu précédent pour cette publication.
Voici à quoi ressemble un véritable reçu pour un patch DELETE article 17 du RGPD — adapté directement du format documenté sur la page de conformité :
{
"name": "gdpr-art17-patient-12348-removal",
"version": 1,
"base_model": "google/gemma-4-E2B-it",
"manifest_sha256": "9abaeaf6c91f8b...",
"previous_manifest_sha256": "8f72b1de4a93c5...",
"created_at": "2026-05-29T03:17:42Z",
"user_id": "compliance-officer-7c4e1a",
"operation": {
"op": "delete",
"entity": "patient-record-12348",
"relation": "diagnosis-association",
"target": "weight-feature-11179-layer-27",
"weight": -1.0
},
"verification": {
"before_feature_11179_score": 17.34,
"before_feature_11179_rank": 1,
"after_feature_11179_score": null,
"after_feature_11179_rank": "ABSENT_FROM_TOP_25",
"perplexity_delta_wikitext103": "+0.02%",
"vindex_sha256_before": "abc12...",
"vindex_sha256_after": "def34..."
},
"weight_attestation_class": "full",
"chain_signature": "sha256(manifest || prev_manifest || user_id || created_at || prev_chain_signature)"
}Cet artefact est vérifiable. Un auditeur n’a pas à faire confiance à nos journaux. Il prend le vindex_sha256_after, récupère le vIndex publié correspondant depuis huggingface.co/Divinci-AI, et vérifie que la feature 11179 de la couche 27 est structurellement absente du top-25. Il prend la chain_signature et la vérifie contre le reçu précédent. La chaîne entière est ancrée à l’extérieur selon un calendrier que le client configure.
Même opération contre un modèle à API fermée. Les champs du reçu ci-dessus changent de trois façons : operation.target devient provider_api_endpoint, verification devient un schéma différent couvrant uniquement les preuves de chaîne de décision, et weight_attestation_class devient decision_chain_only. Le fournisseur du modèle à API fermée n’a pas exposé les poids, donc le reçu le dit. Un auditeur qui veut une preuve au niveau des poids sait alors qu’il doit faire remonter le sujet au fournisseur, pas à nous.
C’est la différenciation que personne d’autre ne livre en 2026. Le camp des évaluations en CI (Braintrust, Humanloop, Patronus) ne s’assied pas sur le trafic et n’émet pas de reçus de décision. Le camp du canary de service (SageMaker Deployment Guardrails[2], KServe, Vertex, BentoCloud, Seldon) émet des journaux de métriques d’infrastructure mais pas de reçus de conformité chaînés par hachage. Le camp de l’observabilité (Arize, Phoenix, Confident, Deepchecks) regarde la sortie mais n’applique rien.
Que vérifie réellement un auditeur ?
Exercice utile : parcourir les questions qu’un véritable auditeur posera, et l’artefact qui répond à chacune.
| Question de l’auditeur | Artefact qui y répond |
|---|---|
| « Quelle version du modèle tournait le 15 mars à 14:22 UTC ? » | Le reçu de l’étape Observer pour cet horodatage, signé et chaîné par hachage. |
| « Quelle évaluation cette publication a-t-elle passée avant promotion ? » | Le reçu de l’étape Filtrer, avec le tableau des ρ de Spearman par tranche et le SHA du jeu de données contre lequel le filtre s’est exécuté. |
| « Une demande d’effacement article 17 du RGPD pour le patient X a-t-elle réellement été appliquée ? » | Le reçu du patch DELETE ci-dessus. L’auditeur vérifie le vindex_sha256_after contre le vIndex publié. |
| « Qui a approuvé cette publication ? Quelle était la justification déclarée pour passer outre le filtre de la tranche licences PI ? » | Le bloc override du reçu de l’étape Filtrer, incluant l’ID utilisateur et la justification en texte libre obligatoire. |
| « À quelle vitesse le rollback s’est-il déclenché, et quelle lecture du moniteur l’a déclenché ? » | Le reçu de rollback de l’étape Observer, avec les trois lectures qualité sous-seuil consécutives et le temps écoulé du rollback. |
| « Montrez-moi les preuves de surveillance post-commercialisation des 90 derniers jours. » | La chaîne de reçus de l’étape Observer. Ancrée à l’extérieur selon le calendrier configuré par le client. |
Ce que l’auditeur n’a pas à faire : faire confiance à notre Datadog. Faire confiance à notre CloudWatch. Faire confiance à une capture d’écran. Faire confiance à un export. Tout l’intérêt du format de reçu est que l’auditeur peut le vérifier indépendamment.
Ce que cela ne résout pas
Trois limites assumées :
Les régressions en API fermée sur le territoire de l’article 17 du RGPD ne sont pas résolvables au niveau de la plateforme. Si vous servez un assistant santé derrière un modèle en API fermée et qu’un patient invoque l’article 17, la plateforme peut attester que le dossier du patient a été retiré de votre magasin de récupération, de votre template de prompt et de vos règles de routage — mais elle ne peut pas attester que les poids du modèle sous-jacent ont oublié les données du patient. Vous avez besoin soit d’une base à poids ouverts, soit d’un engagement du fournisseur sur l’effacement au niveau des poids. Nous le disons dans le reçu.
La documentation est nécessaire mais non suffisante. Un reçu qui prouve qu’un modèle a atteint un seuil ne prouve pas que ce seuil était le bon seuil. Si votre suite de QA notée ne couvre pas la tranche qui compte réellement pour un patient dans votre service, aucun chaînage de reçus ne résoudra cela. Les régulateurs comprennent de plus en plus ce point ; « nous avons passé notre évaluation » n’est plus une réponse de conformité suffisante si l’évaluation était la mauvaise évaluation.
Le format vIndex est mono-fournisseur. Nous l’utilisons parce que c’est la primitive cryptographique la plus concrète disponible aujourd’hui pour la preuve au niveau des poids. Si l’industrie se fixe sur un format différent — model cards avec hashs, schémas d’artefacts publiés par le NIST — le format de reçu devrait évoluer vers cela. Le fond (chaîné par hachage, vérifiable à l’extérieur, conscient de l’attestation de poids) est ce qui est structurant, pas le nom de schéma spécifique. Nous nous attendons à ce que cela change à mesure que le paysage réglementaire et normatif mûrit.
FAQ
Qu’est-ce que l’effacement vérifiable au titre de l’article 17 du RGPD pour les systèmes d’IA ?
L’effacement vérifiable signifie qu’un tiers peut vérifier que les données ont été supprimées sans avoir à faire confiance à vos journaux. Affiner un modèle pour qu’il « oublie » des informations spécifiques ne satisfait pas ce critère — l’information peut refaire surface sous prompt adverse, et il n’y a pas de primitive cryptographique qu’un auditeur puisse vérifier. Un patch DELETE au niveau des poids avec un hash vIndex avant/après publié satisfait, lui, ce critère, car l’auditeur peut réexécuter la vérification contre l’artefact public.
Pourquoi les modèles à API fermée ne peuvent-ils pas satisfaire l’article 17 du RGPD de la même façon ?
Parce que le fournisseur n’expose pas les poids. Sans accès aux poids, aucun tiers — y compris le client utilisant l’API — ne peut émettre ou vérifier un effacement au niveau des poids. La partie chaîne de décision du reçu (quel template de prompt a été utilisé, de quel magasin de récupération les données provenaient, quelles règles de routage étaient actives) reste vérifiable, mais la revendication au niveau des poids ne l’est pas. C’est une limite de ce qui est vérifiable lorsque les poids sont privés, pas une limite du cadre de conformité.
Qu’exige l’Annexe IV de l’EU AI Act, en termes simples ?
L’Annexe IV demande une documentation technique couvrant la logique du système, la synthèse des données d’entraînement, l’usage prévu, les mesures de supervision humaine et la surveillance post-commercialisation. Le piège dans lequel tombent la plupart des équipes est de les traiter comme cinq documents séparés. Le manifeste de publication à l’étape 1 porte les trois premières demandes comme un seul hash ; l’étape Filtrer couvre la quatrième ; les étapes Déployer + Observer couvrent la cinquième. Un seul pipeline ; quatre demandes satisfaites comme sous-produit des opérations normales.
Quelle vitesse de rollback pour les déploiements couverts par HIPAA ?
HIPAA ne spécifie pas de délai de rollback, mais les recommandations du HHS sur la réponse aux violations traitent le temps de confinement comme structurant. Un rollback de l’ordre de la seconde (drainage en vol sur un basculement piloté par manifeste — notre chiffre est d’environ 12 secondes) est structurellement plus rapide qu’un blue-green classique basé sur des métriques d’infrastructure qui dépend de la propagation d’alarmes. À comparer aux postmortems publics : l’incident Cloudflare de juin 2022[4] a pris 44 minutes pour être annulé parce que les ingénieurs se sont marché dessus dans leurs reverts.
Comment NIST AI RMF se projette-t-il sur un pipeline de publication ?
Les quatre fonctions centrales de NIST AI RMF — Gouverner, Cartographier, Mesurer, Gérer — couvrent l’ensemble du cycle de vie de publication, pas une seule étape. Gouverner, c’est la politique de publication documentée plus le workflow de justification des dérogations au filtre (étapes Enregistrer + Filtrer). Cartographier, c’est la suite de QA notée par tranche (Filtrer). Mesurer, ce sont les seuils de Spearman par tranche et le moniteur qualité continu (Filtrer + Observer). Gérer, c’est le chemin de rollback et la chaîne de reçus (Observer). Les quatre sont couvertes lorsque le pipeline émet son jeu complet de reçus.
Références
- EU AI Act. artificialintelligenceact.eu. L'Annexe IV définit les exigences de documentation technique pour les systèmes d'IA à haut risque : logique du système, synthèse des données d'entraînement, mesures de supervision humaine, surveillance post-commercialisation. Sanctions allant jusqu'à 7 % du chiffre d'affaires mondial en cas de non-conformité.
- AWS SageMaker Deployment Guardrails. Use canary traffic shifting + Auto-Rollback Configuration.
TerminationWaitInSecondspar défaut à 600,MaximumExecutionTimeoutInSecondsmax à 1800. Cités comme le canary à métriques d'infrastructure standard du secteur auquel le moniteur qualité de l'étape 4 est comparé. - Accord LLM-juge calibré. Zheng et al., Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena (NeurIPS 2023). Accord global GPT-4-vs-humain > 80 %, avec une variance par catégorie allant du codage (86 %) à la rédaction (36–44 %). Ancre pour la calibration Spearman par tranche qui pilote l'étape Filtrer.
- Panne Cloudflare de juin 2022. Cloudflare outage on June 21, 2022. 44 minutes entre « nous savons ce qu'il faut annuler » et l'annulation terminée parce que les ingénieurs se sont marché dessus dans leurs reverts. Ancre pour l'affirmation « un rollback piloté par manifeste ne peut pas avoir ce mode de défaillance ».
- NIST AI Risk Management Framework. NIST AI RMF. Cadre volontaire — Gouverner, Cartographier, Mesurer, Gérer — devenu la référence de fait des achats d'entreprise pour la gouvernance de l'IA. Volontaire mais appliqué en pratique via les questionnaires de due diligence client.
- HIPAA Privacy Rule. HHS Office for Civil Rights. Divulgation au strict minimum nécessaire, audit d'accès et exigences de délai de réponse aux violations applicables à tout système d'IA qui touche des PHI. Sanctions civiles pécuniaires jusqu'à 1,9 M$ par type de violation par an selon l'ajustement d'inflation des CMP, 2025.
- Article 17 du RGPD (Droit à l'effacement). gdpr-info.eu/art-17-gdpr. Le droit de la personne concernée à obtenir l'effacement de ses données personnelles, et l'obligation du responsable du traitement de démontrer sa conformité au titre de la responsabilité de l'article 5(2). Sanctions allant jusqu'à 20 M€ ou 4 % du chiffre d'affaires mondial annuel.
- Interne — format de reçu vIndex. Le JSON de reçu présenté dans ce billet est adapté du format documenté sur la page de conformité et démontré dans le billet « Deleting Paris from a Language Model ». La chaîne de hash est un SHA-256 sur
manifest || prev_manifest || user_id || created_at || prev_chain_signature. Ancrable à l'extérieur selon un calendrier configuré par le client.
Prochain dans cette série : Automated LLM CI/CD Pipelines With Instant Rollback. Ce billet a montré ce qu’un auditeur veut. Le suivant montre le schéma opérationnel qui fait arriver le reçu sur le bureau de l’auditeur en quelques secondes plutôt qu’en quelques semaines — l’automatisation sous le pipeline en quatre étapes, en se concentrant sur ce qui change lorsque le rollback se déclenche tout seul.
Prêt à Construire Votre Solution IA Personnalisée ?
Découvrez comment Divinci AI peut vous aider à implémenter des systèmes RAG, automatiser l'assurance qualité et rationaliser votre processus de développement IA.
Commencer Aujourd'hui