
Notas del Ciclo de Release — Parte I
La primera vez que intentamos enviar un LLM por un pipeline de CI/CD normal, el build salió verde, el deploy tuvo éxito, y el equipo de soporte al cliente empezó a abrir tickets en siete minutos.
Nada se había “roto.” Los 4.200 tests de integración pasaron. La latencia no había cambiado. La tasa de 200 OK se mantenía estable. Pero en una clase específica de preguntas del dominio legal, el nuevo modelo había empezado silenciosamente a evadir — negándose a comprometerse con una respuesta que la versión anterior había contestado correctamente. Ningún test lo capturó porque todavía no habíamos escrito uno.
Hicimos rollback, y el rollback en sí mismo fue un evento. El artefacto del modelo vivía en tres lugares, el prompt template vivía en un cuarto, las reglas de routing vivían en un quinto, y ninguno sabía nada de los otros. Tardamos algo más de dos horas en volver al estado bueno previo. Los clientes que recibieron una respuesta evasiva durante esa ventana no quedaron impresionados.
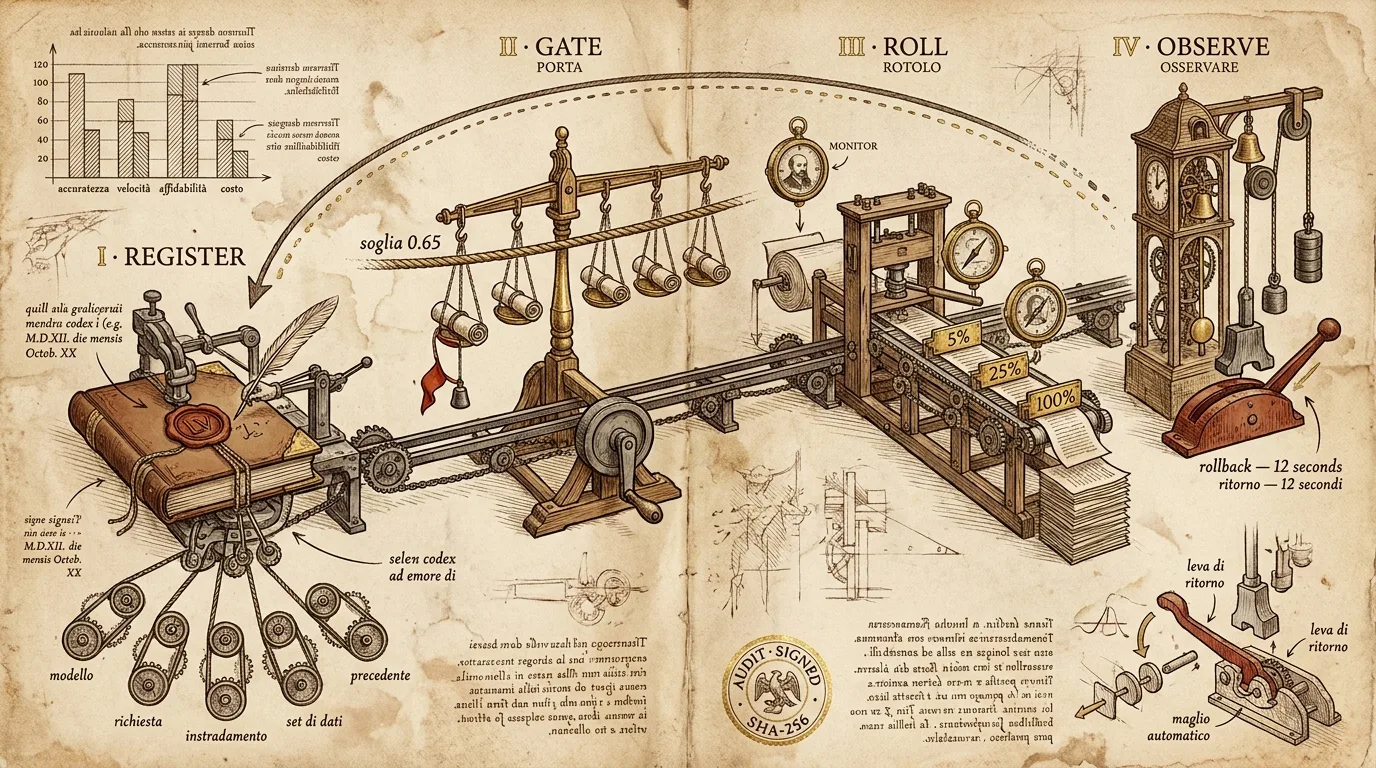
Ese incidente es la razón por la que existe este pipeline. Lo que sigue es el real que usamos para enviar nuestros propios releases, y el que exponemos a través de la API de Divinci para los clientes que envían los suyos. Tiene cuatro etapas — register, gate, roll, observe — y cada paso tiene una ruta de rollback que no depende de que un humano esté despierto.
Las cuatro etapas

Las etapas son intencionalmente rígidas. Cada release pasa por cada etapa en este orden. Una ruta de “hotfix” que se salte la evaluación no existe — intentamos eso una vez.
Etapa 1 — Register
Un release no es un archivo de pesos del modelo. Un release es un manifiesto inmutable que empaqueta:
- El artefacto del modelo (repo de HF + commit SHA, o un patch de vIndex)
- El prompt template (cada variable, cada system message)
- Las reglas de routing (qué clase de tráfico aterriza en qué versión)
- La versión del dataset usada para calcular los umbrales del gate
- El SHA del release anterior, para que el rollback sea inequívoco
curl -X POST https://api.divinci.ai/v1/releases \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{
"model_ref": "Divinci-AI/gemma-4-e2b@a7c91f",
"prompt_template_ref": "templates/legal-qa@v14",
"routing": { "domain": "legal" },
"dataset_version": "scored-qa-medical-v3",
"previous_release": "rel_8f72b1"
}'
# → { "release_id": "rel_a01c66", "manifest_sha256": "9abaeaf6..." }El SHA del manifiesto es el único handle que cualquiera en el pipeline llega a usar. Si dos personas despliegan lo que creen que es el mismo release y los SHAs difieren, el pipeline rechaza el deploy. Ya hemos cazado dos bugs con esta regla.
Etapa 2 — Gate
El gate es la parte que la mayoría de los pipelines de CI hacen mal. Las heurísticas tipo Lighthouse — perplejidad, BLEU, ROUGE — dejarán pasar una regresión si la regresión está concentrada en un dominio. Las puntuaciones agregadas la diluyen.
El gate de Divinci ejecuta la suite de scored-QA con la que se registró el manifiesto del release, y aplica un umbral Spearman por categoría:

El release del gráfico anterior pasaría un gate agregado (media 0,64 es “lo bastante cerca”). Falla el gate de Divinci porque licencias de IP se desploma de un 0,68 previo a 0,41 — exactamente el tipo de regresión localizada que un notebook nunca atrapa.
No inventamos el gating consciente del slice por diversión. Es el modo de fallo nombrado directamente en la cosecha actual de postmortems de LLM. El writeup de Tianpan “The Semver Lie”[6] describe un cambio de prompt que “pasó la revisión de código, se desplegó sin eval gates, llegó a producción sin A/B por usuario, y no disparó ningún rollback automático.” Lo que hizo que ese incidente fuera catastrófico en lugar de meramente molesto fue que la regresión estaba concentrada en un slice — una única clase de user-journey — mientras el agregado se mantenía. Cada herramienta de release de LLM que estudiamos en 2026 o bien hace gate sobre una única puntuación global, o no hace gate en absoluto. Ninguna trocea el gate.
Un fallo de gate no es una advertencia suave. El release_id se marca como gate_fail, el manifiesto se archiva, y ningún comando de deploy lo aceptará. Releases de arranque en frío — un modelo completamente nuevo sin Spearman histórico contra el que comparar — pasan por una ruta única --force-gate-override que exige una justificación escrita; la justificación, el ID de usuario y un gate_override_sha256 van directamente al audit trail. El override existe porque hay situaciones legítimas para él; el audit trail existe porque tu yo futuro necesita poder leer la justificación.
Etapa 3 — Roll
Un canary en Divinci significa tres checkpoints: 5%, 25%, 100%. En cada checkpoint, el pipeline retiene durante el dwell time configurado o el conteo de requests configurado, lo que ocurra después. Por defecto son 4 minutos / 1.000 requests al 5%, 15 minutos / 10.000 requests al 25%.
En cada checkpoint, tres monitores deben aguantar:
- Latencia p95 dentro de 1,2× la p95 del release anterior
- Tasa de 5xx dentro de 1,5× la tasa del release anterior
- Monitor de calidad de output: una reproducción continua de trazas recientes de producción a través del release candidato, puntuadas por el mismo juez calibrado que alimentó la Etapa 2
El tercero es el que ningún otro pipeline de release envía. SageMaker, KServe, BentoML, Vertex AI — todos vigilan latencia y tasa de error. Ninguno puntúa los outputs del candidato contra las preguntas reales que producción está haciendo ahora mismo. El candidato recibe los mismos prompts que el release activo acaba de recibir, los ejecuta en un mirror del 5%, y medimos la Spearman ρ de las respuestas del candidato contra el evaluador calibrado. La tasa de 5xx puede mantenerse limpia mientras el modelo silenciosamente evade, rechaza o alucina. Hemos visto esto ocurrir. El monitor de replay de trazas es lo que lo atrapa.
El conjunto de replay está acotado — limitamos a 50 trazas recientes por slice por checkpoint para que el coste sea predecible. La evaluación tarda unos 90 segundos al 5% de tráfico. Más lento que un canary plano por porcentaje, más rápido que esperar a que un cliente abra un ticket.
# El comando roll es fire-and-forget. El pipeline se sostiene a sí mismo.
curl -X POST https://api.divinci.ai/v1/releases/rel_a01c66/roll \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{ "strategy": "canary", "dwell_5pct_seconds": 240, "dwell_25pct_seconds": 900 }'
# → { "rollout_id": "rol_b3e2", "next_checkpoint_at": "2026-05-26T09:04:00Z" }Etapa 4 — Observe, rollback y el recibo
Esta es la etapa que justifica la existencia del pipeline.
El observador corre continuamente después de que el rollout completa. Calcula una puntuación de calidad de output por minuto sobre una muestra rodante del 5% de replay de trazas. Si la puntuación cae por debajo del umbral de rollback (por defecto: 0,85 del umbral del gate, así que 0,55 si el gate era 0,65) durante tres minutos consecutivos, el rollback se dispara automáticamente. Sin página, sin humano, sin debate.
El rollback en sí mismo es una única instrucción: re-apuntar el routing al previous_release del manifiesto. Porque el release anterior era un manifiesto completamente empaquetado, cada componente — pesos, prompt, routing, dataset — vuelca atómicamente.
Luego se dispara el recibo.
Cada decisión de release — register, gate-pass, gate-fail, gate-override, checkpoint-promote, checkpoint-hold, auto-rollback, manual-rollback — emite un recibo de release: un artefacto JSON-con-SHA-256, encadenado por hash al recibo anterior de este cliente y al recibo anterior de este release, anclado externamente en una programación que el cliente configura.
Cuando el release está respaldado por un modelo de pesos abiertos — Gemma, Qwen, Llama, Mistral, GPT-OSS, cualquier cosa donde los pesos sean direccionables y editables — el recibo embebe una atestación de vIndex: una prueba criptográfica de que los pesos activos en el momento de la decisión son los pesos que el manifiesto registró. Esa es la ruta que satisface las preguntas más duras de compliance (Artículo 17 del GDPR derecho de borrado, procedencia del EU AI Act) porque puedes demostrar no solo qué fue desplegado sino que los pesos subyacentes son lo que dicen ser.
Cuando el release está respaldado por un modelo de pesos cerrados — OpenAI, Anthropic, Google, cualquier cosa servida solo vía una API opaca — el recibo sigue cubriendo la cadena de decisión (qué manifiesto, qué resultado de gate, qué lectura de monitor, qué usuario disparó qué acción) pero no puede atestar los pesos subyacentes, porque no los podemos ver. Eso no es un límite del pipeline; es un límite de lo que es verificable cuando el proveedor no expone los pesos. Los auditores a quienes les importa esa distinción reciben la respuesta honesta en el propio recibo.
De cualquier modo, los auditores hoy reciben logs. Con este pipeline, reciben pruebas de todo lo que es realmente demostrable. No vimos a nadie más en el mercado enviando esto. Esperamos que lo hagan — los plazos del EU AI Act lo hacen eventualmente inevitable. Nosotros elegimos enviarlo ahora.
Estos no son nuestros números — son números publicados de fuentes primarias provenientes de postmortems reales, documentación de plataformas y el framework DORA. El contraste es lo que motiva el diseño de Divinci. El outage de Atlassian de abril 2022[1] tardó doce horas por sitio porque el estado estaba esparcido entre múltiples sistemas que tenían que ser coordinados de vuelta al acuerdo. El outage de Cloudflare de junio 2022[2] tardó cuarenta y cuatro minutos en revertirse porque, en sus propias palabras, los ingenieros se pisaban entre sí los reverts. Las deployment guardrails de canary de AWS SageMaker[4] documentan una espera de terminación por defecto de diez minutos antes de que el rollback complete por completo. El umbral elite de DORA[3] para recuperación de deploy fallido es “menos de una hora” — esa es la barra que se espera que una org de alto rendimiento supere, no el techo.
Doce segundos tampoco es un número mágico. Es el tiempo requerido para que la capa de routing drene los requests en vuelo, intercambie el manifiesto activo y confirme el nuevo estado entre regiones. La parte lenta es el drenaje en vuelo. No hay ruta más rápida que no descarte respuestas a mitad de generación.
Qué es esto, que otras herramientas de release de LLM no son
Estudiamos otras doce herramientas en 2026 antes de construir esta — LangSmith Deployment, W&B Models, MLflow, SageMaker Deployment Guardrails, Vertex AI Endpoints, Seldon Core, BentoCloud, KServe, Humanloop, Braintrust, Patronus AI, Arize Phoenix. Se agrupan en dos campamentos que no acaban de encontrarse.
El campamento de eval-CI — Braintrust, Humanloop, Patronus — hace gate de merges de PR sobre puntuaciones de eval offline. Nunca tocan el servicio en ejecución. Cuando el modelo está en producción y la calidad cae, alertan; alguien más tiene que hacer el rollback.
El campamento de serving-canary — SageMaker Deployment Guardrails, KServe, Vertex AI, BentoCloud, Seldon Core — divide tráfico y hace auto-rollback. Pero todos ellos disparan sobre métricas de infraestructura: latencia p99, tasa de error, alarmas de CloudWatch. Ninguno hace auto-rollback sobre una regresión de calidad. No pueden, porque no tienen un juez corriendo sobre el output de producción.
La costura entre “pasó el eval en el merge del PR” y “canary en vivo puntuado sobre los user journeys que realmente nos importan” es un handoff manual que cada equipo tiene actualmente que salvar por sí mismo. El blog post llama eso el modo de fallo dominante de 2026[6]. Nosotros lo cerramos. Específicamente:
- El gate está troceado. Spearman ρ por dominio contra un evaluador anclado por humanos, no una única puntuación global. La ceguera al slice es lo que cada otro gate tiene.
- El canary observa la calidad del output, no solo el p95. Replay continuo de trazas a través del candidato, puntuado por el mismo juez que alimentó el gate. Esta es la costura faltante.
- Cada decisión emite un recibo de release. Encadenado por hash, anclable externamente, en el formato JSON-con-SHA-256 que respalda nuestras páginas de compliance. Para respaldos de modelos de pesos abiertos — Gemma, Qwen, Llama, Mistral, GPT-OSS — el recibo embebe una atestación de pesos vIndex para que los auditores puedan demostrar cuáles fueron realmente los pesos en vivo. Para respaldos de API cerrada, el recibo cubre la cadena de decisión pero no reclama procedencia de pesos, porque el proveedor no expone los pesos. De cualquier modo, los auditores reciben pruebas de lo que es realmente demostrable, no solo logs.
Eso es todo. Canary genérico, registry de versiones, rollback por métrica de infra — esos son commodity. No escribimos un canary genérico.
Lo que esto no resuelve
Tres limitaciones honestas:
El gate solo es tan bueno como el dataset. Una suite de scored-QA que no cubre el dominio que un cliente realmente usa no atrapará regresiones en ese dominio. Hemos visto esto dos veces. Las dos veces, el primer movimiento del cliente fue enviar una nueva suite de scored-QA, no cambiar el modelo. Ese es el movimiento correcto.
El rollback asume que el release anterior era bueno. Si una regresión ha estado en vivo por tres releases y nadie se dio cuenta, hacer rollback de un release solo te compra un modelo ligeramente menos malo. El audit trail ayuda aquí — puedes hacer rollback a cualquier manifiesto previo por SHA, no solo a N-1.
Los releases de arranque en frío saltan el canary. Un modelo completamente nuevo sin tráfico de producción contra el que comparar no puede ser canary-eado de forma significativa. Forzamos en su lugar un shadow deployment de 24 horas, que observa los outputs sin servirlos. Es más lento y menos conveniente. También es la única respuesta honesta.
La versión más pequeña de esto que puedes correr
Si quieres levantar algo como esto sin usar Divinci, la versión mínima viable es aproximadamente:
- Un registry que almacene modelo + prompt + routing + dataset como un único artefacto inmutable, direccionado por hash de contenido
- Un juez calibrado contra un panel anclado por humanos vía Spearman ρ — y una decisión de gate que consulte puntuaciones por slice, no solo el agregado
- Un splitter de tráfico que retenga en checkpoints y consulte un monitor de calidad acotado por frescura — donde el monitor reproduzca trazas recientes de producción a través del candidato, no solo muestree sintéticas
- Una capa de routing cuyo estado pueda ser intercambiado atómicamente — incluyendo el prompt template, no solo los pesos
- Un audit log que emita un recibo encadenado por hash y anclable externamente para cada decisión de release — más una atestación de pesos embebida cuando el modelo es de pesos abiertos, ya que los releases de API cerrada físicamente no pueden ser atestados a nivel de pesos
La mayoría de los equipos ya tienen (1) y (3). Las partes dolorosas son (2), (4) y (5). La razón por la que Divinci existe es que construimos los cinco para nosotros primero, luego nos dimos cuenta de que todos los demás también iban a necesitarlos.
Si quieres saltarte la construcción, la referencia de la API está aquí, y los endpoints de release en la sección “Release Management” son toda la superficie de este pipeline. El lado del compliance — cómo lucen esos recibos vIndex y cómo mapean al EU AI Act, Artículo 17 del GDPR, HIPAA y NIST AI RMF — está en la página de compliance. Cada comando en este post es un endpoint real.
Referencias
- Atlassian — Post-Incident Review: April 2022 Outage. Del writeup: "El enfoque acelerado de Restauración 2 tardó aproximadamente 12 horas en restaurar un sitio." La restauración completa de 883 sitios de clientes tardó 14 días. El estado esparcido entre infraestructura, backups y validación por sitio empuja el número por sitio a horas en lugar de minutos.
- Cloudflare — Cloudflare outage on June 21, 2022. Línea temporal citada textualmente en el post: "06:58: Causa raíz encontrada y comprendida. Comienza el trabajo para revertir el cambio problemático… 07:42: El último de los reverts se ha completado." Cuarenta y cuatro minutos desde "sabemos qué revertir" hasta "el revert está hecho", en parte porque los ingenieros se estaban pisando entre sí los reverts.
- DORA — Software delivery performance metrics. El umbral elite-performer para "tiempo de recuperación de deploy fallido" está documentado como menos de una hora. Los low performers se miden en semanas-a-meses en los reportes históricos de DORA.
- AWS SageMaker — Use canary traffic shifting y la página complementaria Auto-Rollback Configuration and Monitoring. El ejemplo de
TerminationWaitInSecondses 600 (diez minutos);MaximumExecutionTimeoutInSecondsestá acotado en 1800 (treinta minutos). El rollback se dispara dentro de la ventana de baking una vez que una alarma se activa: "Si alguna de las alarmas se activa durante el período de baking, entonces SageMaker AI inicia un rollback y todo el tráfico vuelve a la flota azul." - Divinci AI — flip de routing atómico vía release manifest. Doce segundos es el tiempo de drenaje en vuelo en un servicio de ~100 réplicas; el intercambio del manifiesto en sí es sub-segundo. El número viene de nuestro propio servicio, no de un benchmark; la arquitectura que lo hace posible es el manifiesto empaquetado descrito arriba (Etapa 1 — Register).
- Tianpan — The Semver Lie: how an LLM minor update breaks production (April 2026). El writeup nombra el patrón de fallo directamente: "pasó la revisión de código, se desplegó sin eval gates, llegó a producción sin A/B por usuario, y no disparó ningún rollback automático." Un post complementario — LLM postmortem template — fields SRE missed — enumera los campos de slice / journey / por usuario que los postmortems actuales omiten sistemáticamente.
Una nota sobre lo que no está en este gráfico. El tiempo de kubectl rollout undo de Kubernetes está gobernado por tus ajustes de maxSurge / maxUnavailable y el warm-up de los pods, no por el comando en sí, y no pudimos encontrar una fuente primaria que publique un número medido del modo en que las cuatro fuentes de arriba lo hacen — así que lo dejamos fuera en lugar de rellenarlo con una estimación.
Próximo en esta serie: 10 fallos de release de CI/CD que hemos cazado en LMs custom, y qué etapa del pipeline atrapa cada uno. Tres de los diez son regresiones conscientes del slice que un gate agregado habría enviado. Dos más son caídas silenciosas de calidad que un canary por métrica de infra habría promovido. El resto son el tipo de modo de fallo que cada pipeline de release se supone que debe atrapar — los listamos porque vale la pena decir en voz alta cuáles, de hecho, atrapa un pipeline con gate agregado por sí mismo.
¿Listo para Construir tu Solución de IA Personalizada?
Descubre cómo Divinci AI puede ayudarte a implementar sistemas RAG, automatizar el control de calidad y agilizar tu proceso de desarrollo de IA.
Comienza Hoy