
Notes from the Release Cycle — Part I
The first time we tried to ship an LLM through a normal CI/CD pipeline, the build went green, the deploy succeeded, and customer support started filing tickets within seven minutes.
Nothing had “broken.” All 4,200 integration tests passed. Latency was unchanged. The 200 OK rate held steady. But on a specific class of legal-domain question, the new model had quietly started hedging — refusing to commit to an answer that the previous version had answered correctly. No test caught it because we had not yet written one.
We rolled back, and the rollback itself was an event. The model artifact lived in three places, the prompt template lived in a fourth, the routing rules lived in a fifth, and nothing knew about anything else. It took just over two hours to get back to the previous good state. The customers who had been served a hedge during that window were not impressed.
That outage is the reason this pipeline exists. What follows is the actual one we ship our own releases through, and the one we expose through the Divinci API for customers shipping theirs. It has four stages — register, gate, roll, observe — and every step has a rollback path that doesn’t depend on a human being awake.
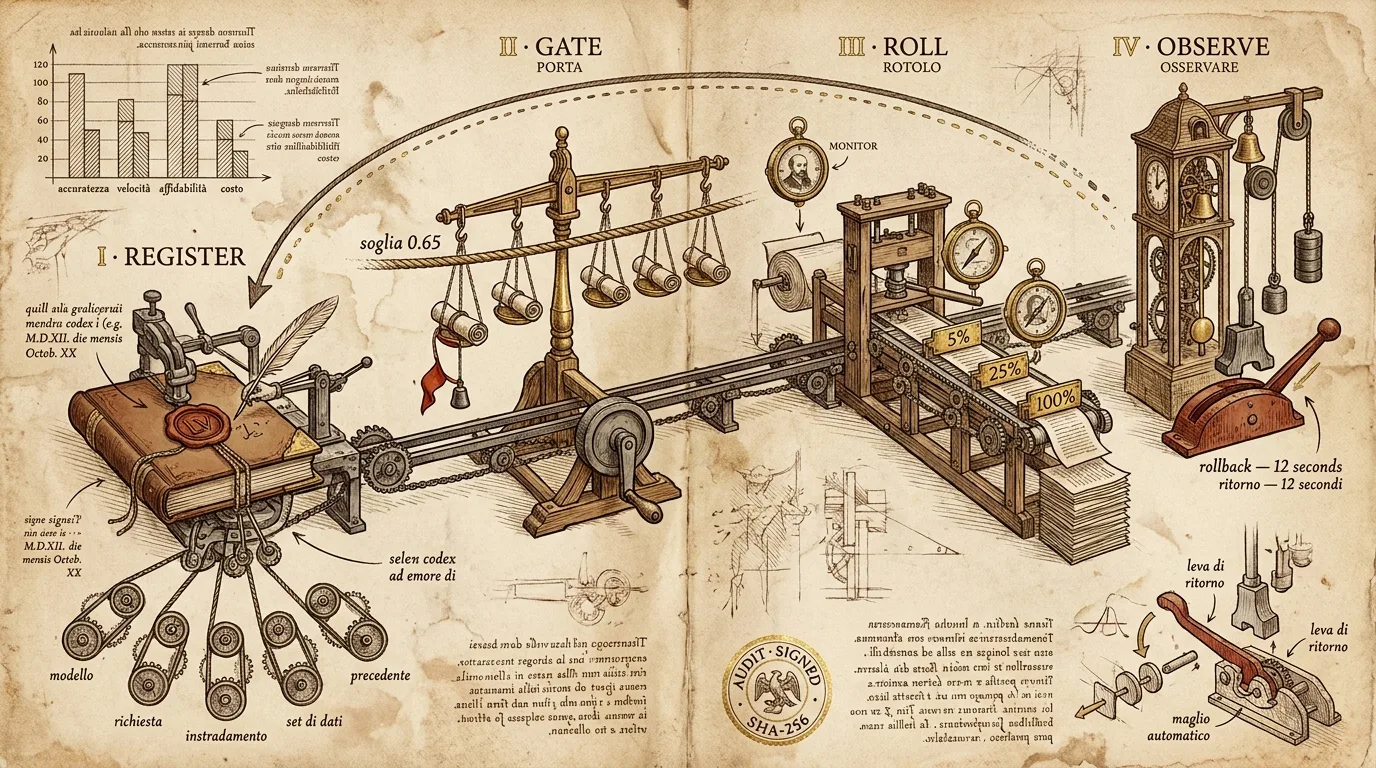
The four stages

The stages are intentionally rigid. Every release passes through every stage in this order. A “hotfix” path that skips evaluation does not exist — we tried that once.
Stage 1 — Register
A release is not a model weight file. A release is an immutable manifest that bundles:
- The model artifact (HF repo + commit SHA, or a vIndex patch)
- The prompt template (every variable, every system message)
- The routing rules (which traffic class lands on which version)
- The dataset version used to compute the gate thresholds
- The previous release’s SHA, so rollback is unambiguous
curl -X POST https://api.divinci.ai/v1/releases \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{
"model_ref": "Divinci-AI/gemma-4-e2b@a7c91f",
"prompt_template_ref": "templates/legal-qa@v14",
"routing": { "domain": "legal" },
"dataset_version": "scored-qa-medical-v3",
"previous_release": "rel_8f72b1"
}'
# → { "release_id": "rel_a01c66", "manifest_sha256": "9abaeaf6..." }The manifest SHA is the only handle anyone in the pipeline ever uses. If two people deploy what they think is the same release and the SHAs differ, the pipeline rejects the deploy. We’ve now caught two bugs with this rule.
Stage 2 — Gate
The gate is the part most CI pipelines get wrong. Lighthouse-style heuristics — perplexity, BLEU, ROUGE — will let a regression through if the regression is concentrated in one domain. Aggregate scores wash it out.
Divinci’s gate runs the scored-QA suite the release manifest was registered with, and applies a per-category Spearman threshold:

The release in the chart above would pass an aggregate gate (mean 0.64 is “close enough”). It fails Divinci’s gate because IP licensing crashes from a prior 0.68 to 0.41 — exactly the kind of localized regression a notebook never catches.
We did not invent slice-aware gating for fun. It’s the directly named failure mode in the current crop of LLM postmortems. Tianpan’s “The Semver Lie” writeup[6] describes a prompt change that “passed code review, deployed without eval gates, hit production without per-user A/B, and triggered no automatic rollback.” The thing that made that incident catastrophic instead of merely annoying was that the regression was concentrated in one slice — a single user-journey class — while the aggregate held. Every LLM release tool we surveyed in 2026 either gates on a single global score, or doesn’t gate at all. None of them slices the gate.
A gate failure is not a soft warning. The release_id is marked gate_fail, the manifest is archived, and no deploy command will accept it. Cold-start releases — a brand-new model with no historical Spearman to compare against — pass through a one-time --force-gate-override path that requires a written rationale; the rationale, the user ID, and a gate_override_sha256 go directly into the audit trail. Override exists because there are legitimate situations for it; the audit trail exists because future-you needs to read the rationale.
Stage 3 — Roll
A canary at Divinci means three checkpoints: 5%, 25%, 100%. At each checkpoint, the pipeline holds for either the configured dwell time or the configured request count, whichever is later. Default is 4 minutes / 1,000 requests at 5%, 15 minutes / 10,000 requests at 25%.
At each checkpoint, three monitors must hold:
- p95 latency within 1.2× the previous release’s p95
- 5xx rate within 1.5× the previous release’s rate
- Output-quality monitor: a continuous replay of recent production traces through the candidate release, scored by the same calibrated judge that powered Stage 2
The third one is the one no other release pipeline ships. SageMaker, KServe, BentoML, Vertex AI — all of them watch latency and error rate. None of them score the candidate’s outputs against the actual questions production is asking right now. The candidate gets the same prompts the active release just got, runs them on a 5% mirror, and we measure the Spearman ρ of the candidate’s answers against the calibrated grader. The 5xx rate can stay clean while the model quietly hedges, refuses, or hallucinates. We’ve watched this happen. The trace-replay monitor is what catches it.
The replay set is bounded — we cap at 50 recent traces per slice per checkpoint so the cost is predictable. Grading takes about 90 seconds at 5% traffic. Slower than a flat percentage-canary, faster than waiting for a customer to file a ticket.
# The roll command is fire-and-forget. The pipeline holds itself.
curl -X POST https://api.divinci.ai/v1/releases/rel_a01c66/roll \
-H "Authorization: Bearer $DIVINCI_API_KEY" \
-d '{ "strategy": "canary", "dwell_5pct_seconds": 240, "dwell_25pct_seconds": 900 }'
# → { "rollout_id": "rol_b3e2", "next_checkpoint_at": "2026-05-26T09:04:00Z" }Stage 4 — Observe, rollback, and the receipt
This is the stage that earns the pipeline’s existence.
The observer runs continuously after the rollout completes. It computes a per-minute output-quality score on a rolling 5% trace-replay sample. If the score drops below the rollback threshold (default: 0.85 of the gate threshold, so 0.55 if the gate was 0.65) for three consecutive minutes, the rollback fires automatically. No page, no human, no debate.
The rollback itself is a single instruction: re-point routing to previous_release from the manifest. Because the previous release was a fully bundled manifest, every component — weights, prompt, routing, dataset — flips atomically.
Then the receipt fires.
Every release decision — register, gate-pass, gate-fail, gate-override, checkpoint-promote, checkpoint-hold, auto-rollback, manual-rollback — emits a release receipt: a JSON-with-SHA-256 artifact, hash-chained to the previous receipt for this customer and the previous receipt for this release, anchored externally on a schedule the customer configures.
When the release is backed by an open-weights model — Gemma, Qwen, Llama, Mistral, GPT-OSS, anything where the weights are addressable and editable — the receipt embeds a vIndex attestation: a cryptographic proof that the active weights at decision time are the weights the manifest registered. That’s the path that satisfies the harder compliance asks (GDPR Article 17 right-to-erasure, EU AI Act provenance) because you can prove not just what was deployed but that the underlying weights are what they claim to be.
When the release is backed by a closed-weights model — OpenAI, Anthropic, Google, anything served only via an opaque API — the receipt still covers the decision chain (which manifest, which gate result, which monitor reading, which user triggered which action) but cannot attest to the underlying weights, because we can’t see them. That’s not a limit of the pipeline; it’s a limit of what’s verifiable when the provider doesn’t expose weights. Auditors who care about that distinction get the truthful answer in the receipt itself.
Either way, auditors today get logs. With this pipeline, they get proofs of everything that’s actually provable. We did not see anybody else in the market shipping this. We expect they will — the EU AI Act timelines make it eventually inevitable. We chose to ship it now.
These are not our numbers — they are published primary-source numbers from real postmortems, platform documentation, and the DORA framework. The contrast is what motivates Divinci’s design. Atlassian’s April 2022 outage[1] took twelve hours per site because the state was spread across multiple systems that had to be coordinated back into agreement. Cloudflare’s June 2022 outage[2] took forty-four minutes to revert because, in their own words, engineers walked over each other’s reverts. AWS SageMaker’s canary deployment guardrails[4] document a default ten-minute termination wait before the rollback fully completes. The DORA[3] elite threshold for failed-deployment recovery is “under one hour” — that’s the bar a high-performing org is expected to clear, not the ceiling.
Twelve seconds is not a magic number either. It’s the time required for the routing layer to drain in-flight requests, swap the active manifest, and ack the new state across regions. The slow part is in-flight drain. There is no faster path that doesn’t drop responses mid-generation.
What this is, that other LLM release tools aren’t
We surveyed twelve other tools in 2026 before we built this — LangSmith Deployment, W&B Models, MLflow, SageMaker Deployment Guardrails, Vertex AI Endpoints, Seldon Core, BentoCloud, KServe, Humanloop, Braintrust, Patronus AI, Arize Phoenix. They cluster into two camps that don’t quite meet.
The eval-CI camp — Braintrust, Humanloop, Patronus — gates PR merges on offline eval scores. They never touch the running service. When the model is in production and quality drops, they alert; somebody else has to rollback.
The serving-canary camp — SageMaker Deployment Guardrails, KServe, Vertex AI, BentoCloud, Seldon Core — splits traffic and auto-rollbacks. But every one of them triggers on infrastructure metrics: p99 latency, error rate, CloudWatch alarms. None of them auto-rollback on a quality regression. They can’t, because they don’t have a judge running on production output.
The seam between “passed eval at PR merge” and “live canary scored on the user journeys we actually care about” is a manual handoff every team currently has to bridge themselves. The blog post calls that out as the dominant 2026 failure mode[6]. We closed it. Specifically:
- The gate is sliced. Per-domain Spearman ρ against a human-anchored grader, not a single global score. Slice-blindness is what every other gate has.
- The canary watches output quality, not just p95. Continuous trace-replay through the candidate, scored by the same judge that powered the gate. This is the missing seam.
- Every decision emits a release receipt. Hash-chained, externally anchorable, in the JSON-with-SHA-256 format that backs our compliance pages. For open-weights model backings — Gemma, Qwen, Llama, Mistral, GPT-OSS — the receipt embeds a vIndex weight-attestation so auditors can prove what the live weights actually were. For closed-API backings, the receipt covers the decision chain but doesn’t claim weight provenance, because the provider doesn’t expose weights. Either way, auditors get proofs of what’s actually provable, not just logs.
That’s it. Generic canary, version registry, infra-metric rollback — those are commodity. We did not write a generic canary.
What this does not solve
Three honest limitations:
The gate is only as good as the dataset. A scored-QA suite that doesn’t cover the domain a customer actually uses won’t catch regressions in that domain. We’ve seen this twice. Both times the customer’s first move was to ship a new scored-QA suite, not to change the model. That’s the correct move.
The rollback assumes the previous release was good. If a regression has been live for three releases and nobody noticed, rolling back one release just buys you a slightly less-bad model. The audit trail helps here — you can roll back to any prior manifest by SHA, not just N-1.
Cold-start releases bypass the canary. A brand-new model with no production traffic to compare against can’t be canaried meaningfully. We force a 24-hour shadow deployment instead, which observes outputs without serving them. It’s slower and less convenient. It’s also the only honest answer.
The smallest version of this you can run
If you want to stand up something like this without using Divinci, the minimum viable version is roughly:
- A registry that stores model + prompt + routing + dataset as a single immutable artifact, addressed by content hash
- A judge calibrated against a human-anchored panel via Spearman ρ — and a gate decision that consults per-slice scores, not just the aggregate
- A traffic splitter that holds at checkpoints and consults a freshness-bounded quality monitor — where the monitor replays recent production traces through the candidate, not just samples synthetic ones
- A routing layer whose state can be swapped atomically — including the prompt template, not just the weights
- An audit log that emits a hash-chained, externally-anchorable receipt for every release decision — plus a weight-attestation embed when the model is open-weights, since closed-API releases physically can’t be attested at the weight level
Most teams already have (1) and (3). The painful parts are (2), (4), and (5). The reason Divinci exists is that we built all five for ourselves first, then realized everyone else was going to need them too.
If you want to skip the build, the API reference is here, and the release endpoints in the section “Release Management” are the entire surface of this pipeline. The compliance side — what those vIndex receipts look like and how they map onto the EU AI Act, GDPR Article 17, HIPAA, and NIST AI RMF — is on the compliance page. Every command in this post is a real endpoint.
References
- Atlassian — Post-Incident Review: April 2022 Outage. From the writeup: "The accelerated Restoration 2 approach took approximately 12 hours to restore a site." Full restoration of 883 customer sites took 14 days. State spread across infrastructure, backups, and per-site validation drives the per-site number into hours rather than minutes.
- Cloudflare — Cloudflare outage on June 21, 2022. Timeline cited verbatim in the post: "06:58: Root cause found and understood. Work begins to revert the problematic change… 07:42: The last of the reverts has been completed." Forty-four minutes from "we know what to revert" to "the revert is done," in part because engineers were stepping on each other's reverts.
- DORA — Software delivery performance metrics. The "failed deployment recovery time" elite-performer threshold is documented as under one hour. Low performers measure in weeks-to-months in DORA's historical reports.
- AWS SageMaker — Use canary traffic shifting and the companion Auto-Rollback Configuration and Monitoring page. The example
TerminationWaitInSecondsis 600 (ten minutes);MaximumExecutionTimeoutInSecondsis bounded at 1800 (thirty minutes). Rollback fires within the baking window once an alarm trips: "If any of the alarms trip during the baking period, then SageMaker AI initiates a rollback and all traffic returns to the blue fleet." - Divinci AI — atomic routing-flip via release manifest. Twelve seconds is the in-flight drain time on a ~100-replica service; the manifest swap itself is sub-second. The number is from our own service, not a benchmark; the architecture that makes it possible is the bundled manifest described above (Stage 1 — Register).
- Tianpan — The Semver Lie: how an LLM minor update breaks production (April 2026). The writeup names the failure pattern directly: "passed code review, deployed without eval gates, hit production without per-user A/B, and triggered no automatic rollback." A companion post — LLM postmortem template — fields SRE missed — enumerates the slice / journey / per-user fields that current postmortems systematically omit.
A note on what isn’t on this chart. Kubernetes kubectl rollout undo time is governed by your maxSurge / maxUnavailable settings and pod warm-up, not the command itself, and we couldn’t find a primary source publishing a measured number in the way the above four sources do — so we left it off rather than fill it in with an estimate.
Next in this series: 10 CI/CD release failures we’ve caught in custom LMs, and which stage of the pipeline catches each one. Three of the ten are slice-aware regressions that an aggregate gate would have shipped. Two more are silent quality drops that an infra-metric canary would have promoted. The rest are the kind of failure mode every release pipeline is supposed to catch — we list them because it’s worth saying out loud which ones an aggregate-gated pipeline does, in fact, catch on its own.
Ready to Build Your Custom AI Solution?
Discover how Divinci AI can help you implement RAG systems, automate quality assurance, and streamline your AI development process.
Get Started Today