
TL;DR
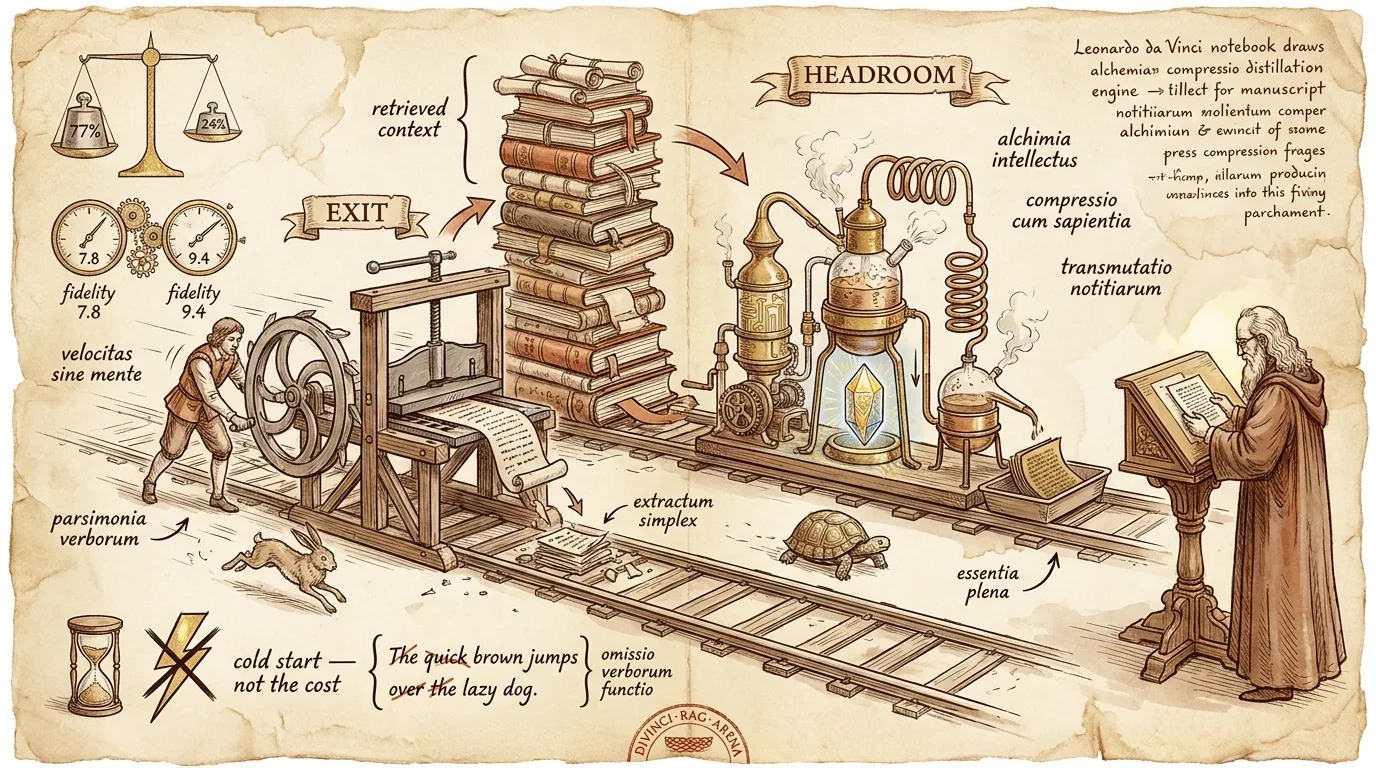
We have a pluggable RAG context-compression slot — retrieved chunks pass through a strategy before they reach the model. Two strategies already lived there: none (passthrough) and EXIT, a ~50-line, zero-dependency extractive compressor that keeps the highest query-relevance sentences. The question we wanted to answer:
Is the open-source Headroom — a local-first compression layer with an ONNX prose model — worth deploying as a third strategy, given we already get compression for free?
So we added Headroom as a strategy, stood up its model as a sidecar, and ran a three-way arena on a real corpus. The result didn’t crown a winner. It drew a map.
| Strategy | Token reduction | Judge score /10 | Added infra |
|---|---|---|---|
none (baseline) | — | 9.00 | none |
| EXIT (in-process) | 77.0% | 7.75 | none |
| Headroom (ONNX sidecar) | 24.4% | 9.38 | a deployed service |
Headroom holds quality and compresses modestly. EXIT compresses aggressively and spends quality. The decision between them is a decision about your corpus and your tolerances — not about which tool is “better.”
The setup
Headroom’s headline is 60–95% fewer tokens. Read the fine print and those numbers come from logs, JSON, and code — payloads that are extraordinarily compressible. RAG retrieval is prose, which Headroom routes to a small ONNX text model (kompress-base). Prose doesn’t compress like a stack trace, so we expected the real ratio to land far below the headline. The point of an arena is to measure that instead of trusting it.
The harness fixes the variable that matters. For eight questions on a nutrition-science corpus, each gets an identical ~900-token context (the relevant chunks plus a pool of plausible-but-marginal distractors, the way real top-k retrieval actually looks). Every strategy sees the same retrieved context, so the only thing that changes is the compression. Then we generate an answer and score it 0–10 against a reference with an LLM judge — the same scored-QA machinery behind our RAG arena work.
Crucially, the harness imports the real production compression code, not a reimplementation. Whatever shipped is what we measured.
Two gotchas a README will never tell you
Before any numbers were trustworthy, the experiment broke twice. Both failures are the interesting part.
1. Headroom protects user messages — so the obvious integration compresses nothing. Our first pass framed the retrieved context as a user message and got back exactly what we sent: zero reduction, every time. Headroom’s router tags user turns as protected content (compress_user_messages defaults to off) and passes them through untouched. That makes sense for an agent loop — you don’t want to mangle the human’s request — but RAG grounding isn’t a user turn. The fix is to frame retrieved context as a system message. Get this wrong and you ship a “compression layer” that silently does nothing while you pay to run it.
2. It won’t touch small contexts. Headroom’s text compressor only engages above a few hundred tokens, and it gets more aggressive as the context grows:
This is a tool built for large agentic traces. Below ~300–500 tokens it does nothing; the value only appears once your retrieved context is genuinely big. Our first run used contexts that were too small and Headroom looked like a no-op — which was a measurement artifact, not a verdict. The numbers above are from the realistic ~900-token re-run.
While we’re collecting honest caveats: Headroom’s target_ratio knob is non-binding for the prose path. We asked for 0.3 and 0.15 and got byte-identical output both times. It’s a budget-driven, autonomous router, not a dial you set.
What the scores actually say
Headroom is quality-safe. 9.38 is statistically indistinguishable from — nominally above — the 9.00 no-compression baseline. Stripping ~24% of tokens cost nothing measurable on this corpus. Function words go; proper nouns, numbers, and the load-bearing acronyms survive.
EXIT is the cheaper, sharper instrument. 77% reduction with no infrastructure at all — but it spent ~1.3 quality points, and unevenly. It scored a perfect 10 on some questions and a 4 on others, because aggressive query-scored extraction occasionally drops the one sentence the answer needed. On a smaller-context run it was worse: there’s no redundancy to safely prune when the context is already tight.
Neither result is a knockout. If you want maximum token savings and can absorb the occasional miss, the free in-process compressor wins on cost and latency. If you can’t afford any quality regression and your contexts are large, the ONNX layer earns its keep.
The scariest number was a cold start
Our first measurement clocked Headroom at ~1,912 ms per call and we nearly wrote it down as the cost of ML compression. It wasn’t. The sidecar runs scale-to-zero, and in the harness each Headroom call was spaced seconds apart by the intervening generate-and-judge calls — so instances kept getting reclaimed and re-spun. The server logs decompose it cleanly:
- Warm compute: 11–22 ms (the ONNX model on CPU)
- Cold start: ~53 s — but only because the model re-downloads at startup, a fixable packaging bug
- Warm round-trip from a distant client: ~240 ms, almost all network
Warm, Headroom is a ~15 ms hop. Its latency is a deployment-configuration question — keep one instance warm — not a property of the compressor. We checked whether moving to an edge container platform would help and it wouldn’t: those instances cold-start too, and our caller already lives in a different cloud, so co-location buys nothing. The honest fix is mundane: pin a warm instance.
It’s a small lesson with a big blast radius. A benchmark that conflates infrastructure state with algorithm cost will mis-rank every option on the table.
The verdict
We shipped Headroom as a selectable compression strategy because it does something real and does it without hurting answers. But the experiment’s most useful output wasn’t a winner — it was the shape of the tradeoff:
- Reach for the in-process extractor when you want big token savings, near-zero latency, and zero new services to operate, and you can tolerate a bounded, occasional quality dip.
- Reach for the ONNX layer when your retrieved contexts are large, quality regressions are unacceptable, and you’re willing to keep a small service warm.
And whichever you choose: frame your RAG context as a system message, make sure the context is big enough to be worth compressing, and never let a cold start audition for the role of your algorithm.
Ready to Build Your Custom AI Solution?
Discover how Divinci AI can help you implement RAG systems, automate quality assurance, and streamline your AI development process.
Get Started Today