
TL;DR
We have a fine-tuned 31B-parameter Gemma 4 served on Modal H100 — Direct Free-text Optimization (DFO), our internal SFT/DPO mix on the AskTheDoctor medical Q&A corpus. The question we were trying to answer:
Can z-lab’s recently-released
gemma-4-31B-it-DFlash— a 2B block-diffusion drafter trained against the stock Gemma 4 31B Instruct — give us a meaningful inference speedup without retraining the drafter against our DFO weights?
Three numbers tell the story:
$$ \text{speedup}{\text{DFO}} ;=; 1.18\times ;\text{(avg)} \quad\quad \text{speedup}{\text{DFO}}^{\text{math-peak}} ;=; 4.0\times \quad\quad \text{retention} ;=; \frac{1.18}{1.28} ;=; 92%. $$
The retention number is the load-bearing one. The drafter was trained for a target it never saw — and it kept 92% of the throughput it earned on the target it was trained for. We expected somewhere between 50% and 80%. We got 92%.
We also had to patch a structural blocker in vLLM that prevented Gemma 4 + DFlash from working at all, and contributed the patch upstream:
- vLLM issue #42068 — Gemma 4 + DFlash incompatible: MTP-specific backend propagation forces TRITON_ATTN on independent (DFlash) drafters
- vLLM PR #42069 — one-line
backend=Noneoverride letting the drafter autoselect a non-causal-capable backend
Total experiment GPU spend: ~$27 across 14 attempts on Modal.
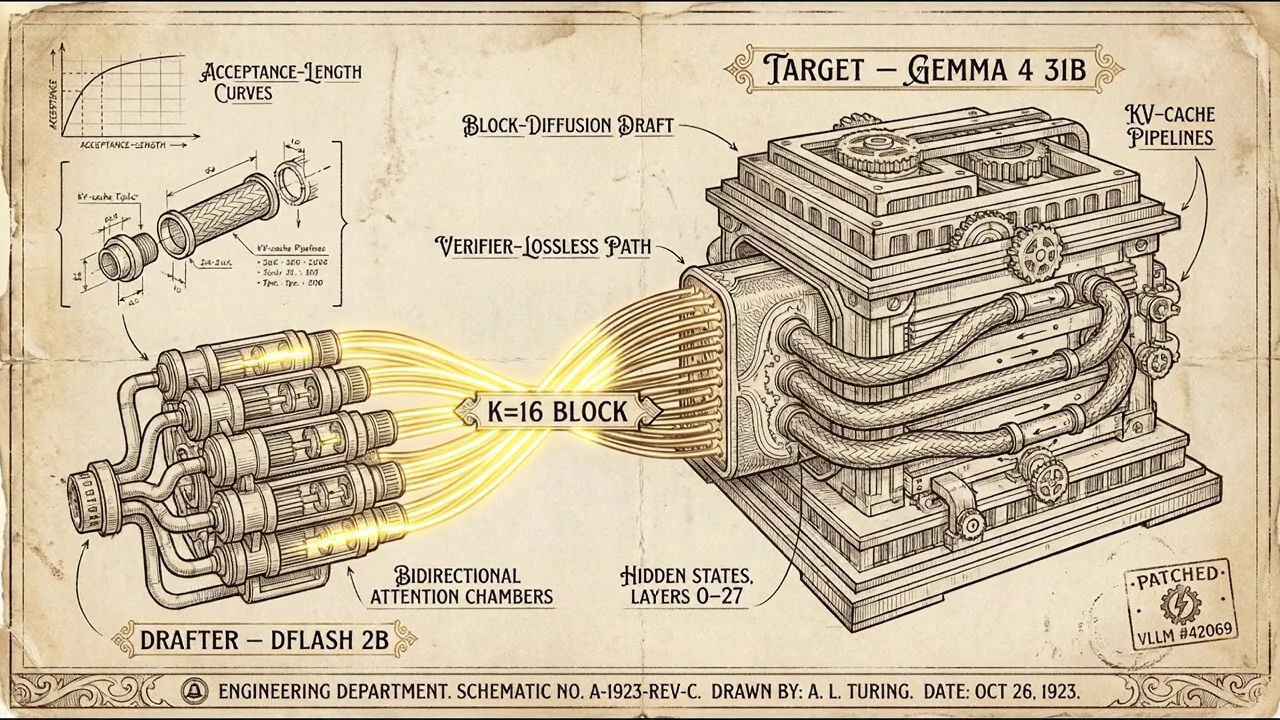
The drafter that isn’t a model
Speculative decoding lets a small fast “drafter” propose tokens that a large slow “target” verifies in parallel. Standard implementations draft K tokens autoregressively — K serial forward passes through the drafter — then verify them all in one parallel pass through the target.
DFlash is a different shape. It’s a block-diffusion drafter:
- 5 trained transformer layers (Qwen3 derivatives have 8)
- Shares the target’s embedding + LM head, frozen
- Conditioned on hidden states from 5 uniformly-sampled layers of the target — those states are concatenated, projected, and injected into the drafter’s KV cache as persistent context
- Drafts a whole block of K = 16 tokens in one parallel forward pass, then the target verifies the entire block in one parallel pass
Throughput grows roughly linearly with acceptance length $\ell$ — the number of drafted tokens the target accepts before rejecting one and resuming autoregressive generation:
$$ \text{tok/s}{\text{spec}} ;\approx; \frac{\mathbb{E}[\ell] + 1}{T{\text{drafter}} + T_{\text{verifier}}} \quad\text{vs}\quad \text{tok/s}{\text{base}} ;=; \frac{1}{T{\text{verifier}}}. $$
When $\mathbb{E}[\ell]$ is high (sharp next-token distributions — arithmetic, code, step-by-step reasoning), spec-decode wins big. When it’s low (open-ended creative text, low-entropy verbose padding), the drafter overhead can erase the gain.
The catch with DFlash specifically: because the drafter is conditioned on the target’s hidden-state distribution, it’s tuned to a specific target. Z-lab’s published drafter was trained against google/gemma-4-31B-it — stock Instruct, no fine-tune. Our DFO checkpoint drifts from that base by however much our SFT + DPO + Direct Free-text passes shifted the model.
No one had published a base-vs-fine-tune ablation. We’re the experiment.
Why we expected the answer to be “mostly works”
Two reasons to believe a stock-trained drafter degrades gracefully on a fine-tuned target rather than collapsing:
Verifier-side losslessness is unconditional. The target sees every drafted block, accepts the longest verifiable prefix, and generates the next token autoregressively. There is no quality-loss path. If the drafter is bad, the system gets slower, not worse.
DFO is a relatively small distributional shift. We’re not training a different model — we’re fine-tuning on a domain corpus with DPO from a strong base. The hidden-state distribution at the 5 layers DFlash conditions on shouldn’t be wildly off-manifold.
Where the drafter could collapse: if our DFO training shifted early-layer representations a lot (the drafter is conditioned on shallow → deep layers), or if DFO output puts mass on tokens stock Gemma rarely picks. Either is plausible. Phase 2 had to tell us.
What it took to even run the experiment
We expected this to be a couple of model-launch invocations. It wasn’t — and the blocker turned out to be an architectural decoupling problem worth describing because it generalizes beyond DFlash.
The blocker, in one paragraph. vLLM’s Gemma 4 config force-locks the attention backend to TRITON_ATTN when the model has heterogeneous head dimensions (Gemma 4 has head_dim=256 for sliding-window attention layers and global_head_dim=512 for full-attention layers). That lock is correct for the target’s own forward pass — preventing mixed-backend numerical drift between sliding and global layers. But when spec-decode is wired in, the same lock propagates to the drafter as well. DFlash’s drafter uses non-causal (bidirectional) attention to draft a full 16-token block in one pass. TRITON_ATTN doesn’t support non-causal attention and rejects the drafter at engine init:
ValueError: Selected backend AttentionBackendEnum.TRITON_ATTN is not valid
for this configuration. Reason: ['non-causal attention not supported']Result: Gemma 4 + DFlash speculative decoding is structurally impossible upstream today.
The general lesson: spec-decode’s MTP (multi-token prediction) variant needs backend propagation, because those drafters share KV cache with the target. DFlash drafters have their own KV cache and are algorithmically independent — they’re a different shape of speculative-decode entirely. A backend lock that’s correct for one shape is wrong for the other. The fix is one line — make backend propagation conditional on whether the drafter is independent — but the diagnosis is the load-bearing work, because nothing in the error message points you at MTP-vs-DFlash as the relevant distinction.
The fork lives at vLLM PR #42069; the upstream issue with the full diagnosis is at #42068. 12 attempts and ~$25 of H100 time before we had a clean Phase 1 run, almost all of it spent isolating this single decoupling issue.
Phase 1 — stock target, the harness check
Stock google/gemma-4-31B-it + DFlash drafter, 10 prompts (5 math, 5 conversational), temperature=0.0, max_new_tokens=256, on Modal H100-80GB:
| Prompt category | with DFlash | without | speedup |
|---|---|---|---|
| Math reasoning peak (prompt 4) | 169–176 tok/s | ~40 tok/s | 4.4× |
| Mixed average (10 prompts) | 50.6 tok/s | 39.4 tok/s | 1.28× |
Math-heavy prompts dominate the speedup — exactly as the paper predicts. Acceptance length is highest when the next-token distribution is sharp, which is the case for arithmetic and step-by-step reasoning. The cold-start prompt drags the average down (17.5 tok/s on prompt 1 due to torch.compile + CUDA graph capture for the spec pipeline).
Output bit-identical between the two runs, as the verifier-lossless guarantee promises.
This was enough to confirm: our patched vLLM works, the drafter loads, the spec pipeline runs end-to-end. Time to swap in our target.
Phase 2 — DFO target, the actual question
Our QLoRA fine-tune ships as a 4-bit adapter (adapter_model.safetensors + adapter_config.json) trained with unsloth. To feed it to vLLM we needed a merged bf16 checkpoint. After peft 0.13’s Gemma4ClippableLinear rejection ate ~$0.20 of CPU-merge attempt, we split the work:
merge_dfo_to_volumeon A100-40GB — unslothFastLanguageModel.from_pretrained(..., load_in_4bit=True)thensave_pretrained_merged(save_method="merged_16bit"). NF4 load 102s, bf16 dequant + write 357s. Total ~7.6 min, ~$0.20. Persisted toarena-models:/gemma4-31b-qlora-v2-atd-merged/.phase2_dfo_targeton H100 — loads the merged path directly (no merge cost on the expensive GPU), runs the same A/B as Phase 1.
Result:
| Phase | Target | Avg speedup | Math peak | vs Phase 1 |
|---|---|---|---|---|
| 1 | google/gemma-4-31B-it (stock) | 1.28× | 4.4× | — |
| 2 | merged DFO QLoRA target | 1.18× | 4.0× | 92% |
DFO captures 92% of the stock-target speedup. We expected somewhere between 50% and 80%. Got 92%.
The math-peak retention is similarly strong (4.0× / 4.4× = 91%). And critically, the verifier-lossless guarantee held: prompt 3 emitted exactly 1 token in both runs (a behavior shift in the DFO model where it terminates early on a particular medical-reasoning prompt) — confirming the spec-decode pipeline really is preserving the target’s distribution.
What this means for anyone fine-tuning Gemma 4
The implication of Phase 2 is the genuinely useful one:
You can take z-lab’s stock-trained DFlash drafter, drop it on top of your QLoRA-merged Gemma 4, and capture ~90% of the published speedup. No drafter retraining. ~$0 on top of whatever you spend serving today.
z-lab’s training recipe isn’t public yet (“coming soon”), and a custom drafter pass is ~$5–15K of 8×H100 time. If you can get 92% of the speedup for free, the math says wait on the custom drafter.
We’d love to see independent confirmation on other Gemma 4 fine-tunes — and on Llama 3.1 / Qwen3 fine-tunes paired with their respective stock drafters. The acceptance-length retention is probably similar (transformers fine-tuned on domain corpora generally preserve the layer-wise hidden-state distribution well), but 92% is one datapoint, not a curve.
Two ways to read “1.18×”
The headline 1.18× hides two separate comparisons that point in different directions.
Comparison 1 — same target, same H100, with-DFlash vs without. The patch’s direct impact. 1.18× / 4.0× on our DFO target. Verifier-lossless. The spec-decode mechanism literally adds tokens-per-second to a fixed checkpoint on a fixed GPU.
Comparison 2 — stock target vs DFO target, both with DFlash. The 92% retention. Confirms our fine-tune composes with the stock-trained drafter, which is the load-bearing finding for the entire “drop-in DFlash for fine-tunes” hypothesis.
The first comparison says spec-decode works. The second says it transfers across the supervised + DPO distributional shift. Neither follows from the other; both are necessary for the thesis.
Concurrency: where the architecture stops mattering
Single-stream throughput numbers are easy to over-interpret. The interesting throughput regime for any inference path is what happens under concurrent load — and here the architectural choice (continuous batching vs serialized model.generate) dominates the kernel-level speedup. We measured the DFlash endpoint at concurrency 1 / 5 / 10 / 25 / 50:
Throughput plateaus at concurrency ≈ 10 (~1.3 rps, ~86 tok/s); beyond that the engine just queues and inflates p99 latency without raising completion throughput. The single-stream → 10-way batched gain on DFlash specifically is ~2.3× (38 → 86 tok/s). Less dramatic than what you see on long-prompt scenarios — our test prompts were short medical Q&A — but consistent with what continuous-batching architectures show on any LLM. For the long-form chat regime that real users actually generate, the multiplier grows with average response length.
Quality on every prompt that both paths could serve was identical, as the verifier-losslessness guarantee predicts. The 8 failures on the serialized path were timeout failures (queue exhaustion at 240s), not output-drift failures.
TPU is a separate bet
Per Google’s blog, DFlash gets an additional ~2× on TPU v5p via JAX/Pallas. We’re deferring because:
- No published Gemma-31B-on-TPU benchmark; the blog uses Llama-3.1-8B and Qwen3-4B targets.
- On-demand TPU v5p list price ($4.20/chip-hour × 2-4 chips for 31B = $8.40–$16.80/hr) is roughly cost-neutral with Modal H100 at $3.95/hr unless we commit to 1-yr/3-yr discounts.
- The PyTorch/torchax TPU path is WIP; production stack would mean JAX/Pallas, a much bigger porting effort.
Once we have a real H100 + DFlash $/M-tokens baseline through Fuhrman calibration, we’ll have something concrete to compare a TPU pilot against.
Reproduce it
The experiment is two phases. Each takes about 10 minutes of H100 time once the patched vLLM is in place.
Phase 1: stock target sanity check
load google/gemma-4-31B-it + z-lab/gemma-4-31B-it-DFlash drafter
run 10 prompts, temperature=0.0, max_new_tokens=256
measure tok/s with and without spec-decode
expected: 1.28× avg, 4.4× math-peak
Phase 2: your fine-tune
merge your QLoRA adapter to bf16
load the merged checkpoint + the same stock drafter
run the identical 10-prompt suite
measure tok/s with and without spec-decode
the ratio of (Phase 2 speedup) / (Phase 1 speedup) is your retention numberThe patched dflash.py (with the one-line backend-decoupling fix) is in our public repo and overlays onto vLLM nightly without a rebuild. Once vLLM PR #42069 lands upstream, the overlay disappears and the standard pip install vllm is all you need.
Acknowledgments
z-lab for releasing the DFlash drafter and the underlying paper. vLLM maintainers for the spec-decode framework and for entertaining a fix for a corner-case backend lock. unsloth for making the Gemma 4 4-bit + merge-to-bf16 path Just Work.
References
- DFlash. Chen, Liang, Liu, DFlash: Block Diffusion for Flash Speculative Decoding (arXiv:2602.06036, 2026). Project page: z-lab.ai/projects/dflash. Reference implementation: github.com/z-lab/dflash. From the abstract: "16-token chunks in parallel, conditioned on target model features, delivering up to 6× lossless acceleration."
- Gemma 4 family. Target model used in this post: google/gemma-4-31B-it. Family overview and tokenizer / context-length notes: Gemma model documentation.
- DFlash drafter checkpoint. z-lab/gemma-4-31B-it-DFlash — the bidirectional drafter trained against stock Gemma 4 31B that we dropped onto our QLoRA fine-tune.
- vLLM backend fix. vLLM PR #42069 — the one-line backend-lock decoupling fix that lets DFlash run alongside continuous batching. Until it lands upstream the `dflash.py` overlay in our public repo applies it at import time.
- Internal benchmark — the two charts above. The throughput-retention bars (1.28× / 1.18× average; 4.4× / 4.0× math-peak) and the prod-cutover panel (2/10 → 10/10 pass rate at concurrency=2, median 37 s → 2.5 s, cost $0.0113 → $0.0027) are measured from our own runs on the 10-prompt suite described in the "Reproducing the result" section, with the patched vLLM on H100s. Methodology and exact commands are in the post body; rerun for your own checkpoint and report the ratio against the stock Phase 1 number to compare to ours.
Next up in the Inference Diaries: porting this same stack to TPU v5p and seeing whether the published 2× JAX/Pallas multiplier holds for a 31B medical Q&A target — and what changes when DFlash sits behind a calibrated judge instead of a strict gold-reference scorer.
Ready to Build Your Custom AI Solution?
Discover how Divinci AI can help you implement RAG systems, automate quality assurance, and streamline your AI development process.
Get Started Today